
Large language models like ChatGPT and Claude are great, but they often don't work well for specific tasks. They might not know your industry's jargon, have trouble keeping formats consistent, or not understand your company's systems.
Fine-tuning solves this, it teaches these general models to do specific tasks really well. This guide shows you how to get started.
Understanding Fine-Tuning
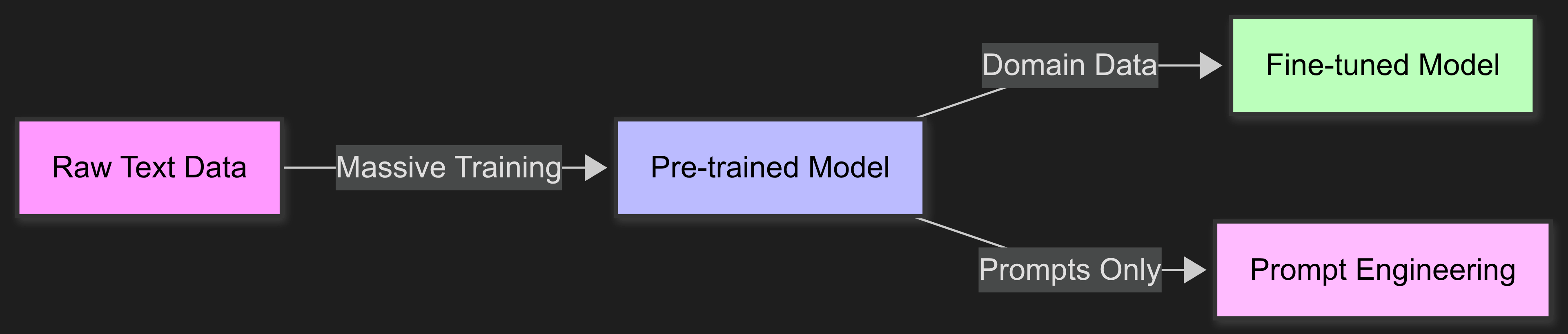
Think of LLMs as smart generalists. They know a lot about everything but need special training for specific areas. There are three main ways to do this:
Pre-training builds the base model from scratch using huge amounts of data. This needs tons of resources and is usually done by big AI companies.
Fine-tuning takes a pre-trained model and keeps training it on your specific data. It's like giving extra training to someone who already knows the basics.
Prompt engineering means writing better instructions without any training. It's quick to try but doesn't always give consistent results.
Fine-Tuning Methods
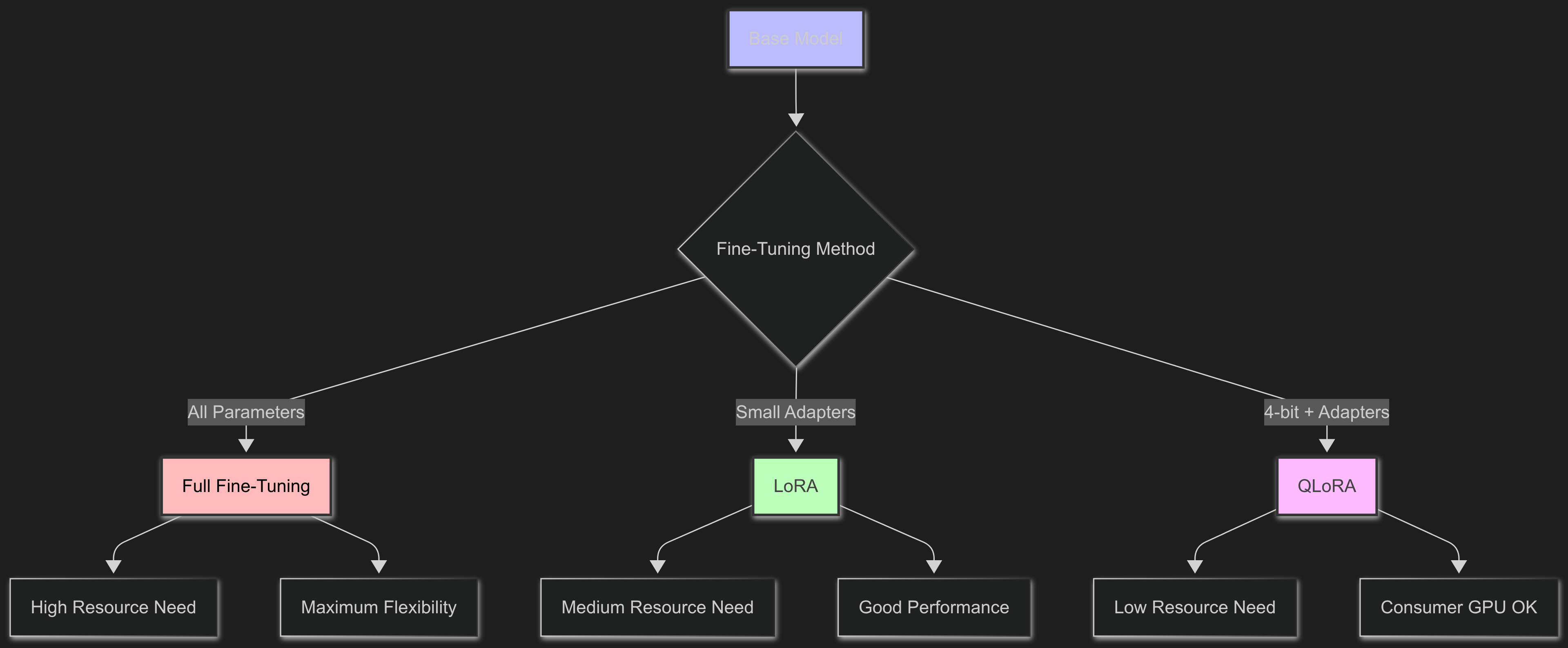
Full Fine-Tuning
This method updates all the model's parameters. It gives you the most control, but needs a lot of computing power and might make the model forget its general skills.
# Full fine-tuning example
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
# All parameters are trainable - billions of them
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Trainable parameters: {trainable_params:,}")
LoRA (Low-Rank Adaptation)
LoRA adds small adapter layers instead of changing the whole model. This makes training much easier while keeping good performance.
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16, # rank determines capacity
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # which layers to adapt
lora_dropout=0.1,
)
model = get_peft_model(model, lora_config)
# Only ~0.1% of parameters need training
QLoRA (Quantized LoRA)
QLoRA combines LoRA with quantization, loading the base model in 4-bit precision while training adapters in higher precision. This lets you fine-tune big models on regular consumer GPUs.
When to Consider Fine-Tuning
Good Use Cases
Fine-tuning works great when you have special terms from fields like medicine, law, or tech where general models don't know the vocabulary. It's also useful when you need consistent formatting for outputs that have to follow specific patterns every time.
For repetitive tasks done thousands of times, fine-tuning can really boost speed and accuracy. Companies with sensitive data that can't leave their servers love fine-tuning because they can run models locally. But you need enough training data - usually at least 1,000 good examples.
When to Avoid Fine-Tuning
Fine-tuning isn't always the answer. With too little data (less than 500 examples), the model won't learn well and might do worse than just using better prompts. When needs change often, keeping multiple fine-tuned models gets messy and expensive. If current models already work fine, or if you don't know how to measure success, fine-tuning probably isn't worth it.
Rule of thumb: If creating 100 perfect examples manually is difficult, fine-tuning probably won't help.
Data Preparation
Good data makes good models. Bad data makes bad models, no matter what technique you use.
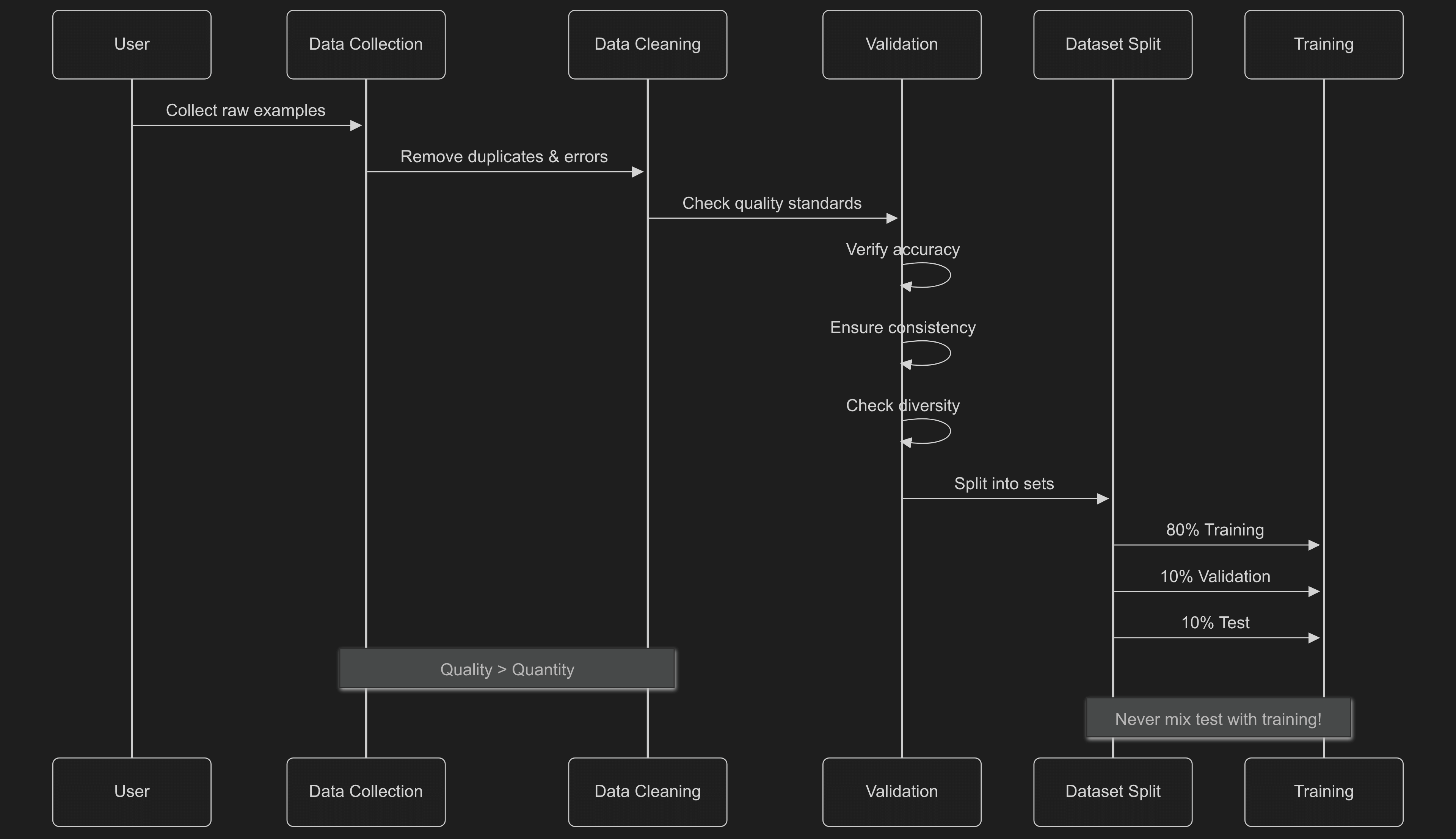
Quality Standards
Data accuracy is the most important thing. Every example needs to be correct and labeled right, because even a little bad data can mess up your model. Quality beats quantity every time - a small set of perfect examples works better than lots of okay ones.
Consistency helps the model learn patterns. When your formatting and style jump around randomly, the model gets confused about what you want. Keep everything consistent - how you label things, how outputs look, even your writing style.
Dataset diversity makes your model stronger. Include weird cases, variations, and different scenarios so your model doesn't break when it sees something new. A model trained only on simple, similar examples will fail when it hits real-world messiness.
Dataset Size Guidelines
How much data you need depends on what you're doing:
- Classification tasks: 500-1,000 examples
- Structured generation: 1,000-5,000 examples
- Complex reasoning: 10,000+ examples
Start with smaller datasets to validate the approach before scaling up.
Data Formats
Instruction-following format:
{
"instruction": "Summarize the customer complaint",
"input": "Ordered item X but received item Y. Very disappointed with service...",
"output": "Wrong item delivered - customer ordered X, received Y"
}
Conversational format:
{
"messages": [
{ "role": "system", "content": "You are a technical assistant" },
{ "role": "user", "content": "How do I implement caching?" },
{ "role": "assistant", "content": "Here are several caching strategies..." }
]
}
Data Cleaning Checklist
Good data cleaning stops lots of problems before they start. First, remove duplicates - repeated examples cause overfitting and mess up your metrics. Then check formatting on everything - if your JSON structure or field names keep changing, you'll confuse the training.
When splitting datasets, keep training and test data totally separate to get real performance numbers. For classification, balance your classes so each type is equally represented - otherwise the model just learns to predict whatever's most common. Last, remove sensitive stuff like personal information and confidential data, both for privacy rules and to stop data leaking through your model.
Choosing Base Models
Open-Source Options
The Llama 3 Series (comes in 8B, 70B, and 405B sizes) is really popular because it works well and has great community support. These models handle multiple languages well and are the first choice for lots of fine-tuning projects because they're both powerful and easy to use.
Mistral and Mixtral models (7B and 8x7B versions) are built to be fast. They're especially good at coding tasks, perfect for technical stuff where you need quick responses.
If you don't have much computing power, Phi-3 models (3.8B and 14B) are surprisingly good for their size. They're made for edge deployment and work well without needing tons of resources like bigger models do.
Proprietary Options
GPT-3.5 and GPT-4 from OpenAI are still the best in raw performance. They cost more, but their simple fine-tuning API means you don't have to manage infrastructure, which is great if you want easy over cheap.
Claude from Anthropic is good at reasoning and has built-in safety features, making it great for sensitive uses. But you can't fine-tune it as easily as other options.
Selection Criteria
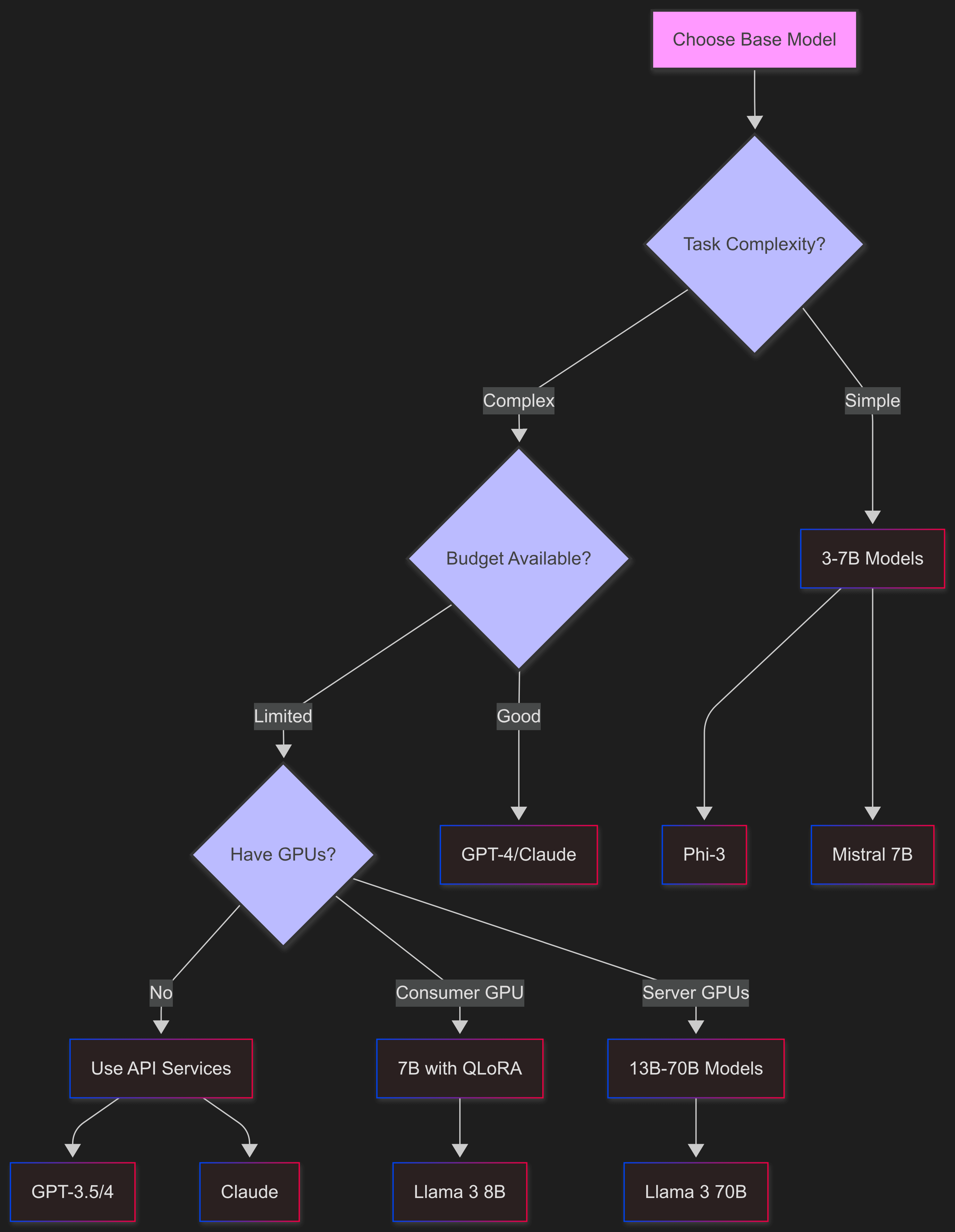
Picking the right base model means juggling different needs. Task complexity decides how big your model needs to be - simple classification might work with 3B parameters, but complex reasoning usually needs 7B or more. Speed requirements usually mean smaller models, since they respond faster and handle more users at once.
Budget matters a lot. Open-source models don't have API costs but you need to pay for servers and maintenance. Proprietary models charge per token but they handle all the infrastructure stuff. And what hardware you have sets hard limits - if you've only got consumer GPUs with 12GB VRAM, big models won't work unless you use tricks like QLoRA.
The Fine-Tuning Process
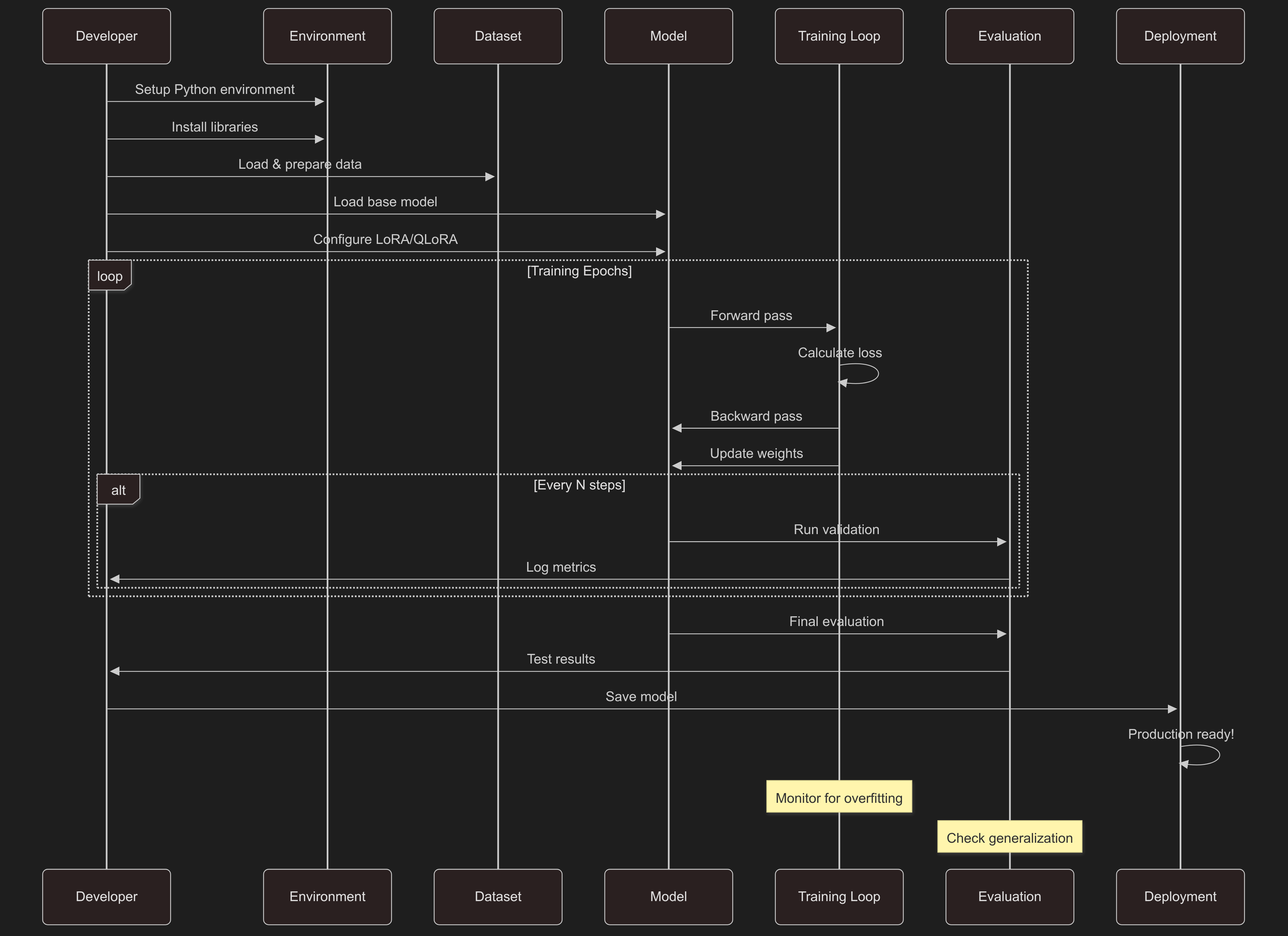
Environment Setup
# Create virtual environment
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# Install required packages
pip install torch transformers datasets accelerate peft bitsandbytes
# For QLoRA support
pip install auto-gptq
Key Hyperparameters
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3, # Typical starting point
per_device_train_batch_size=4, # Adjust based on GPU memory
gradient_accumulation_steps=4, # Simulate larger batches
warmup_steps=100, # Gradual learning rate increase
learning_rate=2e-5, # Standard for fine-tuning
logging_steps=10,
save_steps=500,
evaluation_strategy="steps",
eval_steps=100,
)
Optimization Techniques
Mixed Precision Training:
training_args = TrainingArguments(
fp16=True, # or bf16=True for newer GPUs
# Reduces memory usage by ~50%
)
Gradient Checkpointing:
model.gradient_checkpointing_enable()
# Trades computation for memory
Early Stopping:
from transformers import EarlyStoppingCallback
trainer = Trainer(
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
Tools and Platforms
Development Tools
If you're new to fine-tuning, Hugging Face AutoTrain lets you do it without code and picks the best settings automatically. It handles the technical stuff so you can focus on preparing data and checking results.
Axolotl uses simple YAML config files instead. It's ready for production, supports different training methods, and gives you flexibility for complex cases. Here's what a typical config looks like:
base_model: meta-llama/Llama-2-7b-hf
load_in_4bit: true
adapter: lora
lora_r: 16
datasets:
- path: data.jsonl
type: alpaca
LLaMA-Factory has a web interface that's both easy and flexible. It supports multiple models and has team-friendly features, great for projects where not everyone is comfortable with the command line.
Cloud Platforms
For cloud infrastructure, AWS SageMaker gives you fully managed servers with automatic scaling and enterprise features. It's good for production when you need reliability and scale.
Google Vertex AI works smoothly with Google Cloud Platform, has AutoML features and good monitoring tools. If you're already using GCP, this is usually the easiest choice.
If you're watching costs, Modal and RunPod offer cheap GPU access where you pay only for what you use. They're great for experiments and development when you don't need servers running all the time.
Hardware Requirements
Approximate VRAM needs:
- 7B full fine-tuning: 48GB+
- 7B with LoRA: 16GB
- 7B with QLoRA: 8GB
- 13B with QLoRA: 12GB
Common Pitfalls and Solutions
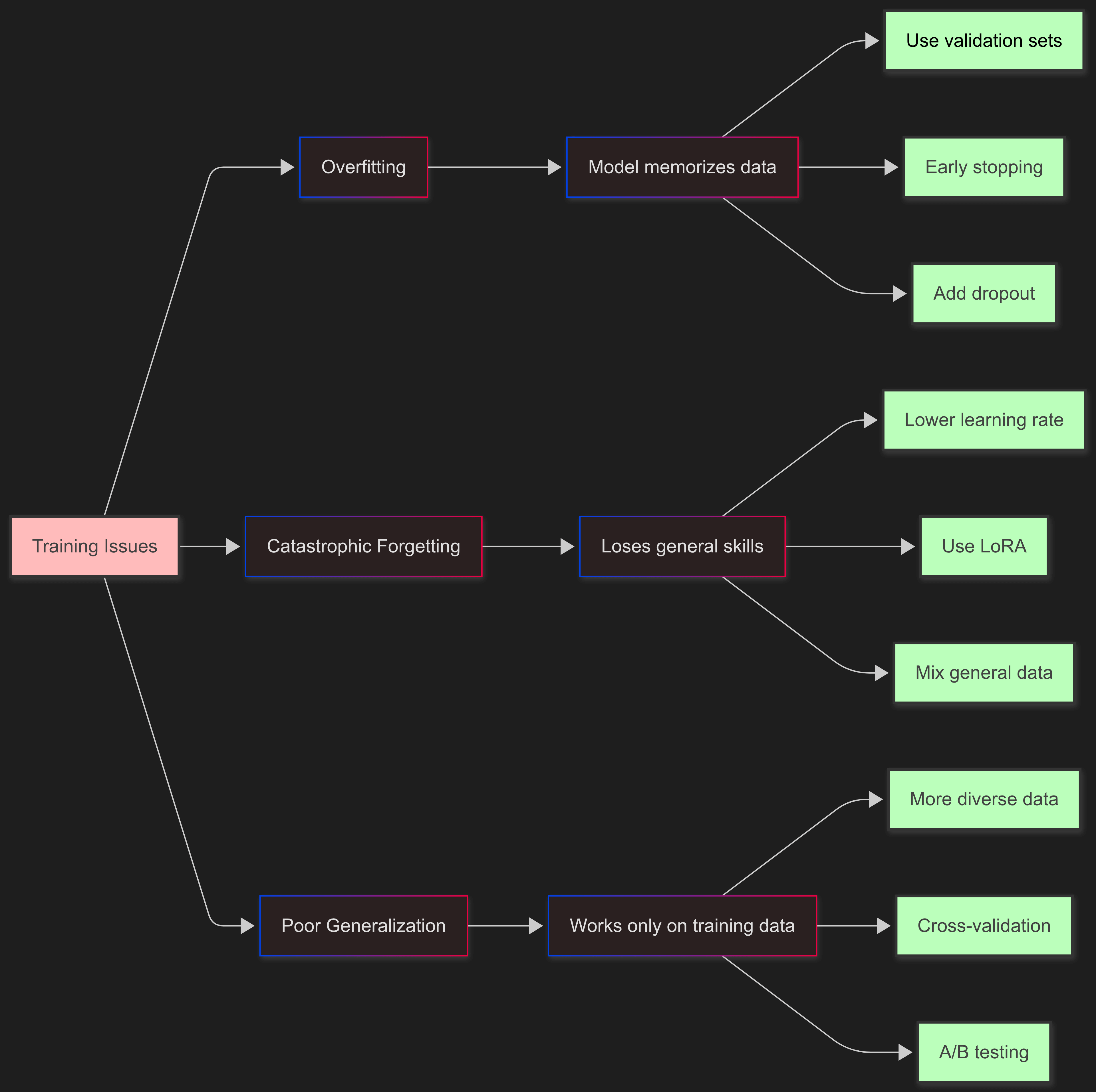
Overfitting
The model memorizes training data instead of learning patterns.
Solutions: The best way to fight overfitting is using validation sets to check how the model does on new data. Early stopping stops training when validation scores stop improving. Adding dropout and regularization helps the model generalize, and mixing in different types of data makes sure it sees lots of examples.
Catastrophic Forgetting
The model loses general capabilities while learning specific tasks.
Solutions: To stop catastrophic forgetting, you need to train gently. Use lower learning rates so the model changes slowly. Use LoRA instead of full fine-tuning to keep most of the original model intact. Mix in some general instruction data to keep broad skills, and techniques like elastic weight consolidation can protect important weights from big changes.
Poor Generalization
Good training metrics but poor real-world performance.
Solutions: To improve generalization, add more diverse data to cover different scenarios. Test regularly on completely new data to see if the model really learned or just memorized. Use cross-validation for better performance estimates, and A/B test in production to see if it really works.
Real-World Examples
Customer Support Automation
Challenge: Generic models lack product knowledge and company policies.
Approach:
- Fine-tuned Llama-2-13B using LoRA
- 5,000 annotated support conversations
- Included product documentation
Results:
- 70% faster response times
- 45% improvement in resolution rates
- 90%+ customer satisfaction
Code Generation for Proprietary Systems
Challenge: Standard code assistants don't understand internal frameworks.
Approach:
def create_training_data(codebase):
examples = []
for file in get_python_files(codebase):
functions = extract_functions(file)
for func in functions:
examples.append({
"instruction": f"Create function: {func.description}",
"output": func.code
})
return examples
Results:
- 80% of generated code runs without modification
- 3x faster development for common patterns
Medical Report Processing
Challenge: Extract structured data from unstructured clinical notes.
Approach:
- Fine-tuned Phi-3 on anonymized records
- Strict output schema validation
- Privacy-preserving training methods
Results:
- 95% extraction accuracy
- Full regulatory compliance
- 60% reduction in processing time
Future Developments
The field is changing fast with some cool trends. Mixture of Experts architectures use different sub-models that turn on based on what you ask, basically giving you multiple fine-tuned models in one. Continuous Learning lets models get better from real-world use without starting training over. Research on Efficient Architectures keeps making smaller models better - some claim GPT-4-like performance with less than 1B parameters. Merge Techniques that combine different fine-tuned models are starting to create systems that are good at lots of specialized tasks.
- Hugging Face Forums - Technical discussions
Key Takeaways
Fine-tuning turns general models into specialized tools, but it's not magic. The most important thing is good, varied training data - without it, no fancy technique will save you. Picking the right technique matters; LoRA or QLoRA work for most cases and balance performance with resource needs. Start small and iterate to test your approach before spending big on data and training. And clear metrics and good testing make sure your training improvements actually work in the real world.
The tech is now easy enough that any organization can make custom models. Whether you're building specialized assistants or solving unique business problems, fine-tuning is a practical way to get AI that does exactly what you need.
Start with QLoRA on a small dataset. Care more about data quality than quantity. Test a lot before going big. Most important - know how you'll measure success before you start.