
Guardrails run before and after model calls to check, modify, or block content. Input guardrails inspect user prompts. Output guardrails operate on streamed chunks and the final text. This article follows a practical outline with working code. VoltAgent provides guardrail helpers and registration points: input bundles (profanity/PII/injection/HTML), output stream/final handlers with abort, and VoltOps tracing for each decision.
TL;DR
- Input: profanity/PII/injection/HTML checks before the model.
- Output: streaming redaction, final validation, and optional abort.
- Actions:
allow,modify,block. All executions are traced in VoltOps.
Why Guardrails In Agents
Prompt text alone cannot enforce policy when tools, memory, or workflows are involved. Guardrails sit on the agent boundary and run every time, regardless of prompt content. They limit input, constrain output, and provide a clear error path when something must be stopped.
Typical failure modes addressed by guardrails:
- Prompt injection that tries to override system instructions
- Leaking PII such as emails, phone numbers, or long digit sequences
- Unbounded outputs that break UI constraints or API limits
- Content that requires a disclaimer or moderation step
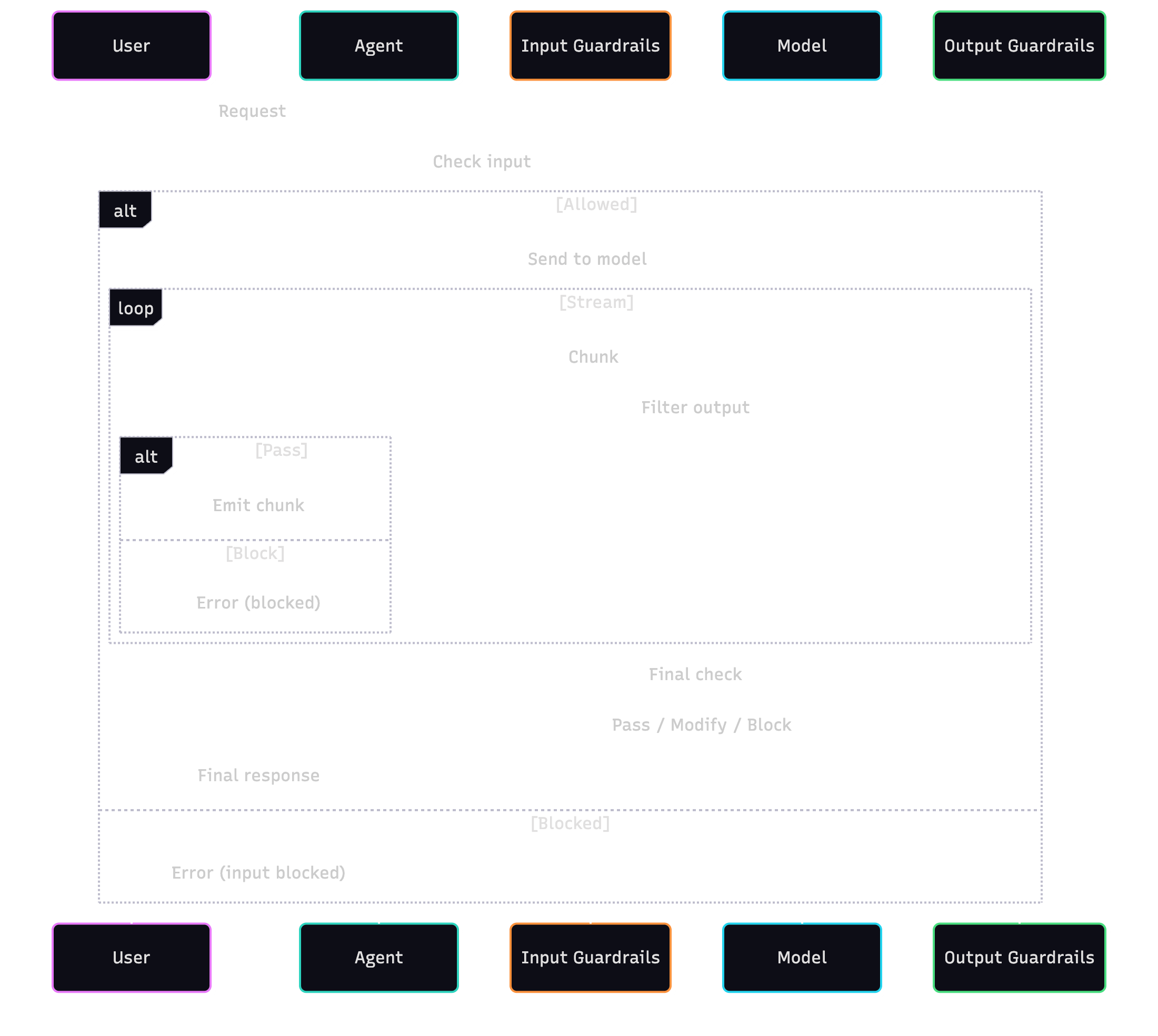
Guardrails Overview
- Input (once): sequence of handlers before sending to the model.
- Output (stream): per‑chunk transform or abort.
- Output (final): validate/replace after streaming completes.
Return values decide the action. A blocked action throws and is visible in traces with the guardrail name and message.
Core Concepts
- Stream handler vs. final handler: transform as chunks arrive, then validate the final text.
- Abort: terminate a stream immediately with a message when a rule is violated.
- State sharing: stream handler and final handler share a simple state object for counters and context.
Provided Guardrails
- Sensitive Number: redact long digit sequences during streaming.
- Email/Phone Redactors: mask PII in streamed text.
- Profanity: redact or block with a mode switch.
- Max Length: truncate or block after a character limit.
- Input Bundles: profanity mask, PII mask, prompt‑injection phrases, HTML sanitizer.
See website/docs/guardrails/built-in.md for options.
Add Guardrails To An Agent
Register input guardrails on the agent during construction. They run in order before any model call and can block or rewrite input.
import { Agent, createDefaultInputSafetyGuardrails } from "@voltagent/core";
import { openai } from "@ai-sdk/openai";
const inputGuardrails = createDefaultInputSafetyGuardrails();
export const support = new Agent({
name: "Support",
instructions: "Answer user questions",
model: openai("gpt-4o-mini"),
inputGuardrails,
});
Output Redaction And Limits
Use streaming guardrails to modify or abort chunks as they arrive. Use a final handler to validate the complete text or enforce a policy before returning.
import {
createSensitiveNumberGuardrail,
createMaxLengthGuardrail,
createOutputGuardrail,
} from "@voltagent/core";
import { openai } from "@ai-sdk/openai";
import { Agent } from "@voltagent/core";
const digits = createSensitiveNumberGuardrail({ minimumDigits: 6, replacement: "[redacted]" });
const maxLen = createMaxLengthGuardrail({ maxCharacters: 280, mode: "truncate" });
const disclaimer = createOutputGuardrail({
id: "require-disclaimer",
handler: async ({ output }) => {
if (typeof output === "string" && !output.includes("Not financial advice")) {
return { pass: false, action: "block", message: "Response must include disclaimer" };
}
return { pass: true };
},
});
export const comms = new Agent({
name: "Comms",
instructions: "Be concise",
model: openai("gpt-4o-mini"),
outputGuardrails: [digits, maxLen, disclaimer],
});
During streaming, abort(reason) can terminate immediately. VoltOps records the error with the guardrail span.
Guardrails In Tools
Validate tool inputs and gate sensitive actions. Example: block navigation unless a flag is set by a prior approval step.
import { createTool } from "@voltagent/core";
import { z } from "zod";
export const navigate = createTool({
name: "navigate",
inputSchema: z.object({ url: z.string().url() }),
handler: async ({ input, context }) => {
const approved = context.context.get("approved") === true;
if (!approved) throw new Error("Navigation requires approval");
// ...perform action
return { ok: true };
},
});
Guardrails In Workflows
Workflows can include a guard step that validates content or context, then suspend for review if needed. Resume with an approval payload to continue or branch to a rejection path.
import { createWorkflowChain } from "@voltagent/core";
import { z } from "zod";
export const publish = createWorkflowChain({
id: "publish-article",
name: "Publish Article",
input: z.object({ text: z.string() }),
result: z.object({ status: z.enum(["approved", "rejected"]) }),
}).andThen({
id: "guard-output",
handler: async ({ input, suspend }) => {
if (input.text.includes("PII:")) {
const approval = await suspend("manager-approve", {
reason: "Detected PII tag",
});
if (!approval?.approved) return { next: "done", data: { status: "rejected" } } as const;
}
return { next: "done", data: { status: "approved" } } as const;
},
});
Observability With VoltOps
- Each guardrail execution creates a span with name, action, pass/fail, and optional metadata.
- Aborts mark the span as error with the supplied reason.
- Traces show whether modification happened during streaming or final validation.
Minimal inspection example (pseudo-usage in a test):
const res = await comms.streamText("Card 5555444433339999");
let text = "";
for await (const t of res.textStream) text += t;
// text contains "[redacted]"; the trace includes the guardrail action and lengths.
Performance And UX Trade‑Offs
- Prefer light input checks first; push heavier checks to output handler.
- Use
truncateinstead ofblockwhen UI requires a response but you need a cap. - Cache results for expensive verifiers when input repeats.
- Keep the guardrail order stable. Earlier redactions change text that later guardrails see.
Testing And Evals
- Add cases for injection phrases, profanity, and PII.
- Record guardrail messages; assert on them in tests.
- Pair with eval suites to track regression.
Example using Vitest style assertions:
it("redacts digit sequences", async () => {
const r = await comms.streamText("use 5555444433332222");
let body = "";
for await (const c of r.textStream) body += c;
expect(body).not.toMatch(/\d{4}\s?\d{4}\s?\d{4}/);
});
Migration Tips
- Start with output length and PII redaction on endpoints that return text to users.
- Add prompt‑injection guardrails to public chat endpoints.
- Restrict sensitive tools and require an approval flag in context.
- Keep guardrails close to agents instead of scattering regex checks across handlers.
Real‑World Patterns
- Safe RAG: input bundle + output PII + citation requirement guardrail.
- Approval Gate: input check → draft → human approval → tool call.
- PII‑Aware Support: input HTML sanitizer + profanity mask + output max length.
Sketch for “Safe RAG” with a retriever agent:
const agent = new Agent({
name: "RAG",
model: openai("gpt-4o-mini"),
tools: [retrieverTool],
inputGuardrails: createDefaultInputSafetyGuardrails(),
outputGuardrails: [
createSensitiveNumberGuardrail({ minimumDigits: 6 }),
createMaxLengthGuardrail({ maxCharacters: 1200, mode: "truncate" }),
],
});
FAQ
- What if a guardrail blocks too often? Tune phrases/thresholds and switch from
blocktoredactwhere acceptable. - How do multiple guardrails combine? They run in order; a block stops execution; state can pass from stream to final.
- Can I write custom guardrails? Yes, use
createInputGuardrailorcreateOutputGuardrailand return an action.