
Introduction
If you look around, it's pretty much impossible not to have heard something about AI, especially these Large Language Models (LLMs), right? As if you knew these GPTs, Llamas, Claudes, and all that. As if these have already become part of our lives.
It's lovely to ask an LLM one question and get one answer. But how about giving it your entire customer support operation? Or asking it to handle a big research project from beginning to end? This is where a standalone LLM, no matter how smart, falls a little short. It's like having a super-powerful brain but no arms or legs.
A single LLM is like a wonderful solo musician. It can perform wonders. But sometimes you require a symphony-an orchestra where various instruments play in coordination with each other in perfect harmony. That is precisely what LLM Orchestration is!
And right at this critical point, in comes LLM Orchestration. No more just whispering things to an LLM; it is making it talk to a bunch of other tools and data sources and even other LLMs to perform bigger, more complex, and more useful tasks.
In this post, we're going to break down this "LLM Orchestration" thing for you.
Explore Orchestration Components
What's This LLM Orchestration Thing Everyone's Talking About?
Okay, we're tossing the term "orchestration" around and all that, but what is it, actually? Let me try defining it in the simplest way:
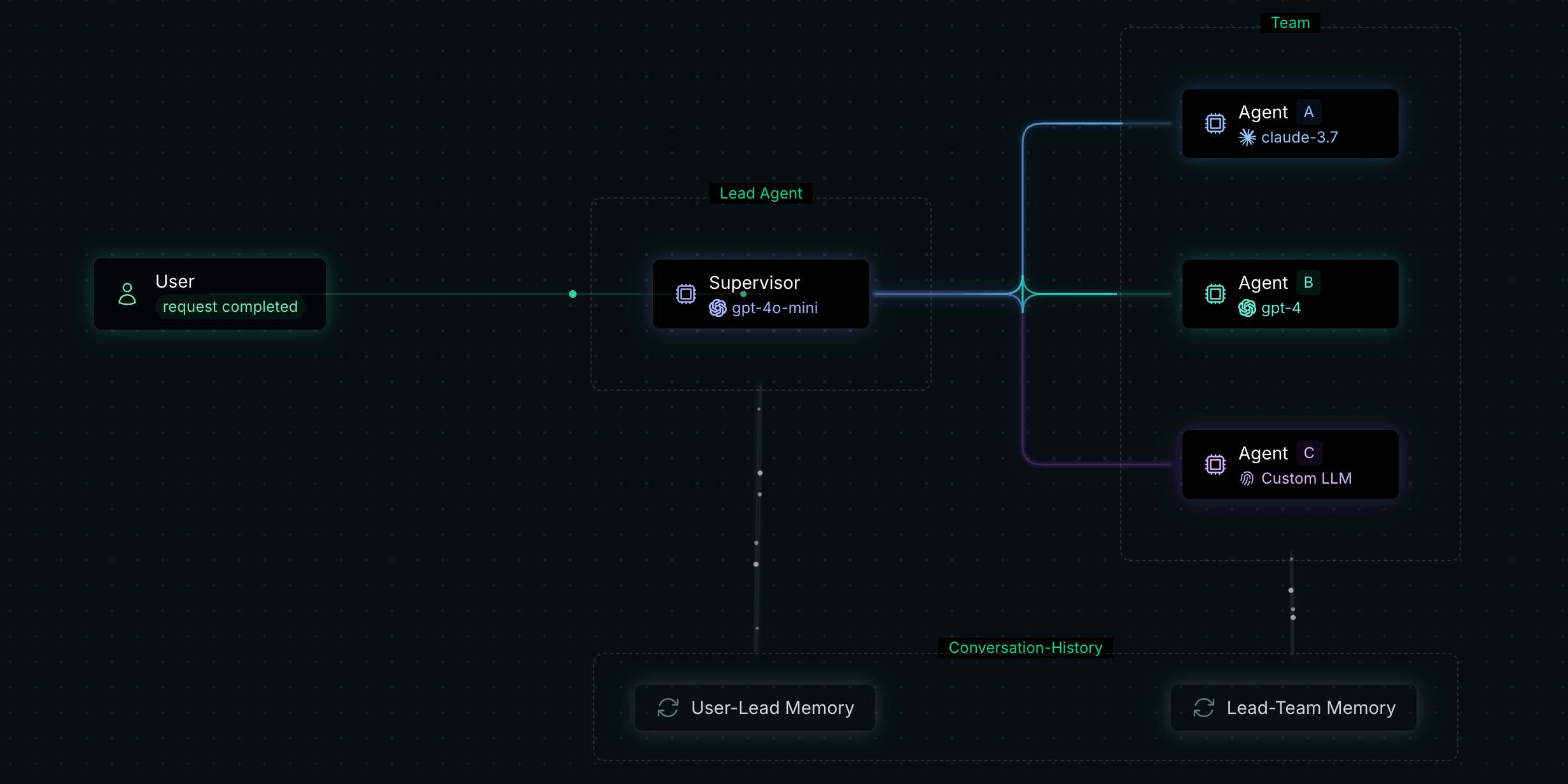
LLM Orchestration is basically the art of intelligently coordinating and managing one or more LLM calls with other third-party tools (whether it's a search engine, a database, or maybe an API you built yourself), data sources, and other software components.
So you hand an LLM and say: "Listen, pal, this is your assignment. But in order to finish off that assignment, you would utilize this tool there, fetch that data from there, then take the result and pass it on to this other LLM that will mold it like so." It's all about instructional flow management.
An orchestrator is similar to a chef at a restaurant. They have great ingredients; the LLMs are amazing, yet they need to also direct the other tools in the kitchen, knives, ovens – our "tools" – and other cooks, possibly other services or LLMs, to prepare a delicious meal, the successful outcome. No one would work like this, right?
So, what is the key point here?
- To break down the big and complicated problems into smaller, bite-sized pieces that LLMs can handle.
- To enhance the wonderful language capabilities of LLMs with real world-knowledge and actions. And let's be honest, LLMs don't know everything or can't do everything. yet. -To build even more trustworthy, consistent-and-most importantly "stateful" (the ability to "remember" the situation) AI applications. That is, make systems that do not leave a conversation midway and say, "what are we talking about?" and can remember context. That's probably one of the most important points for me because in my very first experiences playing around with LLMs, that "memorylessness" really drove me nuts!
In short, thanks to orchestration, LLMs no longer remain simple machines that produce theoretical knowledge and become more sophisticated assistants capable of performing practical tasks. Is the picture clearer now?
But Why Bother? Aren't LLMs Good Enough on Their Own?
Now, some of you may ask, "Hey, aren't those LLMs quite already smart enough? Why bother with all these chains, tools and stuff, making things even more complicated?" Indeed, LLMs achieve incredible things on their own. However, real world problems may quite often result in a "devil is in the details" situation.
Some Key Points Where LLMs Alone Can Struggle and Orchestration is We Give It a Call "Must Have":
-
The Memory Issue and That Forgetfulness! They have a "context window." They can remember only a certain part of a conversation or text in their "mind." If the conversation gets a little too long, and the text to be analyzed is huge, they might forget the things at the very beginning. You know when you're telling your friend something and then five minutes later they're like, "What did you say again?" Sort of like that. I have to admit, I was quite disappointed when first I encountered this. I felt really like speaking with a different person each time..
- What Orchestration Does: That is where it comes in and manages the conversation history. If necessary, it summarizes the old data and reminds the LLM, or splits long texts into pieces, gets each piece analyzed separately, and then combines the outcomes together. In short, it expands the LLM's "memory."
-
Real-World Knowledge and the Up-to-Date Problem: "I Only Know Things Up to September 2021."
Most LLMs are trained up until a specific date. So, you cannot expect it to know about yesterday's headlines, the latest technologies, or your business's most recent product prices. In case you ask it, "What is the weather today?" it would probably say something like, "I do not know beyond my cut-off date."
- What Orchestration Does: It connects the LLM to the external world!
This also feeds in the latest and freshest flow of information to the LLM via "tools" like search engines, news APIs, or databases within the company.
It can even further allow it to act by having the LLM act with such tools, such as sending an email or creating a calendar event. They have so cool names for this, like "Retrieval Augmented Generation," which, I think is one of the most revolutionary things.
- Complex Tasks and Step-by-Step Thinking Ability LLMs are excellent at text generation, sure. But if you present them with a multi-step, complicated task such as "Make a business plan for me, analyze the risks for this plan, and prepare presentation slides," they can get stuck sometimes. Even if they complete each step flawlessly, they may not be able to link these steps together in a logical flow.
- What Orchestration Does : Well, here come the "chains" and the "agents". The huge, hard job will be divided up into smaller, tractable sub-lets.
An LLM does its thing, that output feeds in to be an input for the next thing, maybe another LLM or a tool comes in at that point. That's what that factory assembly line did: each station did their piece, and at the end, this finished product. When first exposed to using agents, I felt like I had literally given the LLM a brain and a bunch of arms and legs!
- Consistency and Reliability: "What Will It Say This Time?" LLM responses sometimes tend to be a bit. variable. You may get two entirely different answers if you ask the same question twice, once today and once tomorrow. While this may be a wonderful feature for creative tasks, it becomes quite a pain when you want consistency and accuracy.
- What Orchestration Does: It can arrange for mechanisms that verify the outputs ensuring that, for example, the response from the LLM is in the right format or even ask the LLM to repeat the question with a different approach if the answer doesn't do justice. In other words, it tries to reduce those "I wonder" moments.
- Cost and Performance: Every Click is Gold!
Operating LLMs, most especially the big and powerful ones, is not cheap, in the first place. Every API call is going to be an arm and a leg. If you are generating dozens of LLM calls just to wastefully do some task, both your bill increases, and your application slows down.
- What Orchestration Does: it optimizes the calls. Either probably to some easy tasks it is dealing with a more trivial, rule based rather than querying the LLM. Or maybe it is caching results of oft used things so that it doesn't trouble the LLM again and again. In other words, it considers both your time and pocket.
LLMs are not magic wands. They are great tools, of course, but they are no panacea. The key to their successful use is knowing what they are good at and what they are not, and supplementing the weaknesses with intelligent approaches such as orchestration.
You can sense that orchestration is far from any "add-on." In fact, it's often a requirement to make LLMs actually powerful and useful applications. So, what does this thing called orchestration comprise? What are the building blocks that come together to create magic?
The Basics of LLM Orchestration: Chains, Agents, Memory, and More!
Excellent, we understand why orchestration is such a key thing. So, how does this system function? What are the fundamental building blocks? Now, let's have a closer look at some of the concepts you'll encounter most frequently, and these will be the crux of it all.
Chains: The Dance of LLM Calls
One of the simplest orchestration concepts is called "chains." You string multiple steps together as implied by its name. Those steps could be LLM calls, using a tool, or just about any form of data processing step.
-
Simple Chains: The most straightforward logic. Ask a question to an LLM, receive its answer, forward that answer to another LLM, receive its answer. and so forth. You could, for instance, first summarize some text and then convert that summary into keywords.
-
Smarter Chains: Add a bit of logic. For example: If the LLM's answer is 'yes,' do this; if 'no,' do that. Or you take multiple results generated by one LLM and tell another LLM, "Choose the best one among these."
-
One of my earliest "Aha! All I had just used a chain to get them to classify a user's request with some initial classification and then send it to a specific LLM for that classification. All I had done was get them to share the workload!
Your Orchestration Starting Point
What's your primary goal with LLM Orchestration right now?
Recommended Steps:
- 1. Get a Strong Foundation: Focus on understanding what LLMs are, basic prompt engineering, and the core problem orchestration solves.
- 2. Key Component Deep Dive: Use the 'Explore Orchestration Components' widget above to understand Chains, Agents, Tools, Memory, and RAG individually.
- 3. Read Introductory Articles: Look for beginner-friendly blog posts or documentation that explain orchestration concepts with simple examples.
Agents & Tools: Letting LLMs Make the Decisions!
This is where things get really interesting. Agents transform LLMs from purely taking commands into creatures that think for themselves, decide how to apply which tool when, and make a plan to reach a goal.
-
What is an Agent? At the heart of an agent is an LLM. This LLM understands the task, thinks over what tools it has, and goes through a thought process very much like, "To achieve this task, I first need to do this, then I ought to use this tool, and with the output from that, I should do that."
-
What Can Tools Be? Anything you can imagine!
-
Web Search: Searching the internet for up-to-date information.
-
Calculator: For mathematical operations. (Yes, LLMs can sometimes mess up even simple math; a calculator tool is a lifesaver!)
Code Interpreter: See running the code that's generated by the LLM and the result it produces.
-
Database Querying: Retrieving information from your company's database.
-
API Calls: Using the API of any external service, such as the weather, maps, and calendar, etc.
-
Custom Tools: Your own custom-written tools that accomplish some specific task.
-
ReAct (Reason + Act) Pattern: Agents most often apply this very common thought pattern.
The LLM reasons, like: What should I do? Which tool should I select? Then it acts-that is to say, applies the tool. Then observes-looks at what the tool provides and repeats the cycle as long as needed to be done. When I first saw this, I felt like I was literally reading an AI's "inner voice." Very impressive!
Suppose that you asked an agent, "Find the lowest fare flight ticket from Los Angeles to San Francisco for tomorrow and send it in my mail." Then the agent might think like this:
-
Thought: "I need to find a flight ticket. For this, I should use the 'flight search' tool."
-
Action: Utilizes the flight search tool to look for Los Angeles to San Francisco tickets for tomorrow's date.
-
Observation: Receives the results from the tool (a list of flights and prices).
-
Thinking: "I should select the cheapest one and send e-mail. I should select by price, select the cheapest, and then send the e-mail."
-
Action: Selects the cheapest ticket, passing this selection onto the send e-mail function. And voilà! Ticket information right into your inbox. How cool is that?
-
Memory: No More "What Were We Talking About?" As we said, LLMs have a short memory. "Memory" modules are there to solve this problem. They contextualize the LLM by keeping the record of a process or a conversation.
-
Conversation Memory The most common type. This saves all the conversation with the user or important parts of it. Now the LLM can reference earlier steps in the conversation to say something like, "Regarding that X topic you brought up earlier."
-
Entity Memory: Pick up and store important entities mentioned in the conversation (names of people, places, products, etc.) and information related to them.
-
Knowledge Graph Memory: The LLM can make deeper inferences by storing even more complex relationships in a graph structure.
-
Long-Term Memory with Vector Databases: A bit more advanced, but really powerful. You can take any document, old conversation or text data of your interest and convert them into numerical forms called "vector embeddings" and store them in special databases such as Pinecone, Chroma, FAISS, etc. When an LLM gives a response to a question, the database offers the most relevant information, which is incorporated into the response from the database.
This is RAG (Retrieval Augmented Generation) itself! It becomes as if your own personal Google.
Data Ingestion & Retrieval (RAG): Feed LLMs Your Own Information
This is actually very close to the Memory topic, especially the vector databases part. RAG is the key to making LLMs talk to your own private data, company documents, content on your website, or any pool of information.
-
How the Process Works (Simplified):
-
Data Loading: You are loading your own documents (PDF, TXT, HTML etc) in the system
-
Chunking: The inputted data is subdivided into smaller bits.
-
Creation of Embeddings: The text is transformed into a numeric vector, which semantically interprets it with the help of an embedding model, itself an LLM.
-
Stored in Vector Database: These vectors and the pieces of text itself are stored inside the vector database.
-
When a User Query Comes In: - The user's question is also passed through the same embedding model, and a query vector is created.
This question vector is compared against the other vectors stored in the database. The words in the text that are semantically closest-that is, most relevant to the question-are located. These relevant pieces, combined with the user's original question, are input into an LLM as a "prompt."
The LLM utilizes the question and this additional information to create far more precise, contextually appropriate responses to your data.
When I first implemented RAG and had an LLM talk to my own notes, I was just blown away. It felt like the LLM became an extension of my brain!
-
Callbacks & Logging: What's Going On Behind the Scenes?
As the flows of orchestrations become more complex, questions like "What step are we on now?", "What was the LLM response?", "What tool did we use?" matter a great deal. Callbacks and logging enable you to trace this process, debug issues, and examine performance. Frameworks like LangChain have this built in.
If you don't log a complex orchestration flow, finding the problem when something goes wrong is like looking for a needle in a haystack. Setting up a good logging strategy from the start is very important. Trust me on this!
Think of an LLM as a super-smart intern. They can write, summarize, and even code a bit. But to tackle a big project, they need a manager (the orchestrator) to break down tasks, provide the right documents (tools/RAG), help them remember past conversations (memory), and ensure their final work is polished and useful (parsing/output formatting).
Dive Deeper: Key Orchestration Concepts in Action
Think of it like this: your LLM is a brilliant chef (GPT-4, Claude, etc.), but it only knows how to cook what's in its recipe book (its training data). If you ask for a dish using ingredients it hasn't seen (recent news, your company's private data), it might struggle or make something up.
RAG is like giving that chef a tablet connected to a massive, constantly updated grocery database and your personal pantry list. Here's a simplified flow:
-
You Ask a Question: "What were our Q3 sales figures for Product X based on the latest internal report?"
-
Retrieve Relevant Information: The LLM retrieves relevant information from the database or external sources.
-
Generate Response: The LLM uses the retrieved information to generate a response.
-
Output: The response is presented to the user.
What's Out There? Popular LLM Orchestration Framework
When it comes to bringing LLM orchestration to life, developers have several powerful frameworks and tools at their disposal. These tools aim to simplify the complexities of building, managing, and monitoring sophisticated AI applications. Popular open-source frameworks like LangChain and LlamaIndex provide comprehensive components for creating chains, managing agents, and implementing Retrieval Augmented Generation (RAG) pipelines. They are widely adopted and boast extensive community support and a wealth of examples.
Alongside these established players, other specialized tools and frameworks continue to emerge, each offering unique strengths. For developers particularly focused on TypeScript and seeking strong built-in observability from the ground up, VoltAgent presents a compelling option.
VoltAgent: A TypeScript Framework with a Keen Eye on Observability
VoltAgent is an open-source TypeScript framework specifically designed for building and orchestrating AI agents and LLM applications. It provides developers with the tools to create sophisticated workflows where LLMs can interact with various data sources, external APIs, and other services. A key focus for VoltAgent is its observability features. The VoltOps LLM Observability Platform allows developers to visualize the entire execution flow of their agents on an n8n-style canvas. This makes it significantly easier to debug, trace decision-making processes, monitor performance, and understand LLM costs associated with each step in an agent's operation. This visual approach to observability helps demystify the "black box" nature of complex LLM chains and agentic behaviors, making development and maintenance more manageable.
If you're looking for a modern, TypeScript-first approach to LLM orchestration with built-in visual debugging and tracing, VoltAgent is definitely worth exploring. You can find its documentation here and the project on GitHub.
Getting Your Hands Dirty: Tips for Starting with LLM Orchestration
Alright, theory is great, but how do you actually start building with these concepts? It might seem daunting, but here are a few practical tips:
- Get a Strong Foundation:
-
How Do LLMs Work? It's very useful to know, at a basic level, what LLMs are, how they are trained, and what "prompt engineering" means. Explore the question, "How do I get the answer I want from an LLM?"
-
Python (or JavaScript): Orchestration frameworks that are super popular nowadays, such as LangChain, are usually based on Python or JavaScript. Familiarity with at least one of them will make your life much easier. Python seems to be ahead of other languages in this field regarding community support and library diversity.
- Find a Problem to Solve (Or Make One Up!):
It often makes more sense to begin with a practical problem than to get mired in theory. A question might be: "Could I automate this annoying X task with LLMs and orchestration?" or "What if I made my own personal Y assistant?"
- My first project was simple: an agent that would fetch new articles on my favorite blogs, summarize them for me, and rank them according to my interests. It wasn't that complicated, but it was enough to send me on a path of discovery of basic concepts!
- Select an Orchestration Framework and Start Tinkering:
-
LangChain, which we mentioned earlier, is overall an excellent starting point for newcomers; their documentation is quite extensive, and they have numerous pre-written examples (cookbooks).
-
Installation: Go ahead and install the selected framework: in most cases, you begin with something such as:
pip install langchain..
Write Your "Hello World": Create a chain that makes a very simple LLM call. Then gradually add a tool to it, get acquainted with a memory module.
- Proceed Step by Step, Start Simple:
-
Don't try to build the most complex agent or the largest RAG system right away. First:
-
Create a simple chain: Ask the LLM a question, get its answer. - Add a tool: Make the LLM use a calculator or search the web. - Add memory: Make a chatbot that remembers the conversation history.
-
Try RAG on your own data: Upload a small text file through a tool like LlamaIndex and ask the LLM questions about this file.
-
Every small success will motivate you to take the next step. I also got confused at first by trying to do everything at once, but then things got easier when I said, "Hold on, let me just get this one step done first."
- Review lots of sample code and watch tutorials
- The official documentation for tools like LangChain and LlamaIndex is worth its weight in gold. They contain hundreds of sample codes and use cases.
- You can find countless tutorials and guides on those topics on YouTube, Medium, and any number of blogs. Searching for something like "LangChain tutorial for beginners" suffices.
- Look at open-source projects on GitHub. How others use these tools is highly instructive.
- Be Patient and Have Fun! Building with LLMs and orchestration is an evolving field. There will be trial and error. Embrace the learning process, celebrate small wins, and don't be afraid to experiment. The AI landscape is moving fast, and being hands-on is the best way to keep up.
Your Orchestration Starting Point
What's your primary goal with LLM Orchestration right now?
Recommended Steps:
- 1. Get a Strong Foundation: Focus on understanding what LLMs are, basic prompt engineering, and the core problem orchestration solves.
- 2. Key Component Deep Dive: Use the 'Explore Orchestration Components' widget above to understand Chains, Agents, Tools, Memory, and RAG individually.
- 3. Read Introductory Articles: Look for beginner-friendly blog posts or documentation that explain orchestration concepts with simple examples.
Wrapping It All Up: The Future is Orchestrated
Yes, dear friends, we have started our journey into this exciting world called LLM orchestration. We found that it is not only a collection of cool technical terms but actually one of the keys to artificial intelligence becoming smarter, more capable, and useful in every area of life.
Now it is your turn. What are you going to do with this knowledge? What problem are you going to sweat and grind to solve? Probably you will begin with a tiny hobby, or maybe you will lay the foundation for the next big startup. Whatever happens, do not stop learning, trying, and, above all, dreaming.