
Vector databases and large language models (LLMs) are two concepts you hear about constantly in AI applications. Let's explore how they work, why they complement each other, and what advantages they offer in real-world scenarios.
What Are Vectors and Why Do We Use Them?
Think of a vector as a list of numbers that comes out of machine learning models. These numbers represent the meaning of unstructured data (text, images, audio) in numerical form.
For example, when you feed "happy person" into a model, it converts this phrase into a multi-dimensional vector. Similarly, "very happy person" produces another vector, and the distance between these two vectors would be quite small. This is why vectors are so powerful at capturing semantic similarity.
The Role of Vector Databases
We use vector databases to store and quickly query these vectors. With a vector database, you can:
- Store embeddings (vectors)
- Perform similarity searches
- Manage them in production with CRUD operations (create, read, update, delete)
Redis is one of the leading solutions here. With Redis Search, you can do secondary indexing on JSON data and support vector searches. They're even working with Nvidia on GPU-based indexing.
How Vector Databases Actually Work
Vector databases use a sophisticated pipeline to enable fast similarity search:
The Indexing Process
When you add vectors to the database, they go through indexing algorithms that transform high-dimensional vectors into compressed, searchable structures:
- Random Projection: Projects high-dimensional vectors to a lower-dimensional space using a random projection matrix
- Product Quantization: Breaks vectors into chunks and creates representative "codes" for each chunk
- HNSW (Hierarchical Navigable Small World): Creates a tree-like structure where each node represents a set of vectors, with edges representing similarity
The Query Pipeline
- Indexing: The query vector gets indexed using the same algorithm as the stored vectors
- Searching: The system compares the indexed query to indexed vectors using approximate nearest neighbor (ANN) algorithms
- Post-Processing: Retrieves and potentially re-ranks the final nearest neighbors based on your requirements
Vector Databases vs Traditional Databases
Vector databases aren't just databases with vector support bolted on. They're fundamentally different:
Traditional Databases
- Designed for exact matches on scalar data
- Use B-trees and hash tables for indexing
- Query with SQL for precise filtering
- Struggle with high-dimensional data
Vector Databases
- Built for similarity search on vector embeddings
- Use specialized indexing (HNSW, LSH, IVF)
- Query by finding nearest neighbors
- Excel at semantic search and AI applications
The key difference? Vector databases are purpose-built to handle the complexity and scale of vector data. They can:
- Insert, delete, and update vectors in real-time
- Store metadata alongside vectors for filtering
- Provide distributed and parallel processing
- Use advanced indexing for faster searches at scale
Vector Databases in VoltAgent
If you're building AI agents with TypeScript, VoltAgent makes it incredibly easy to add vector database capabilities. Here's how the RAG (Retrieval-Augmented Generation) flow works in VoltAgent:
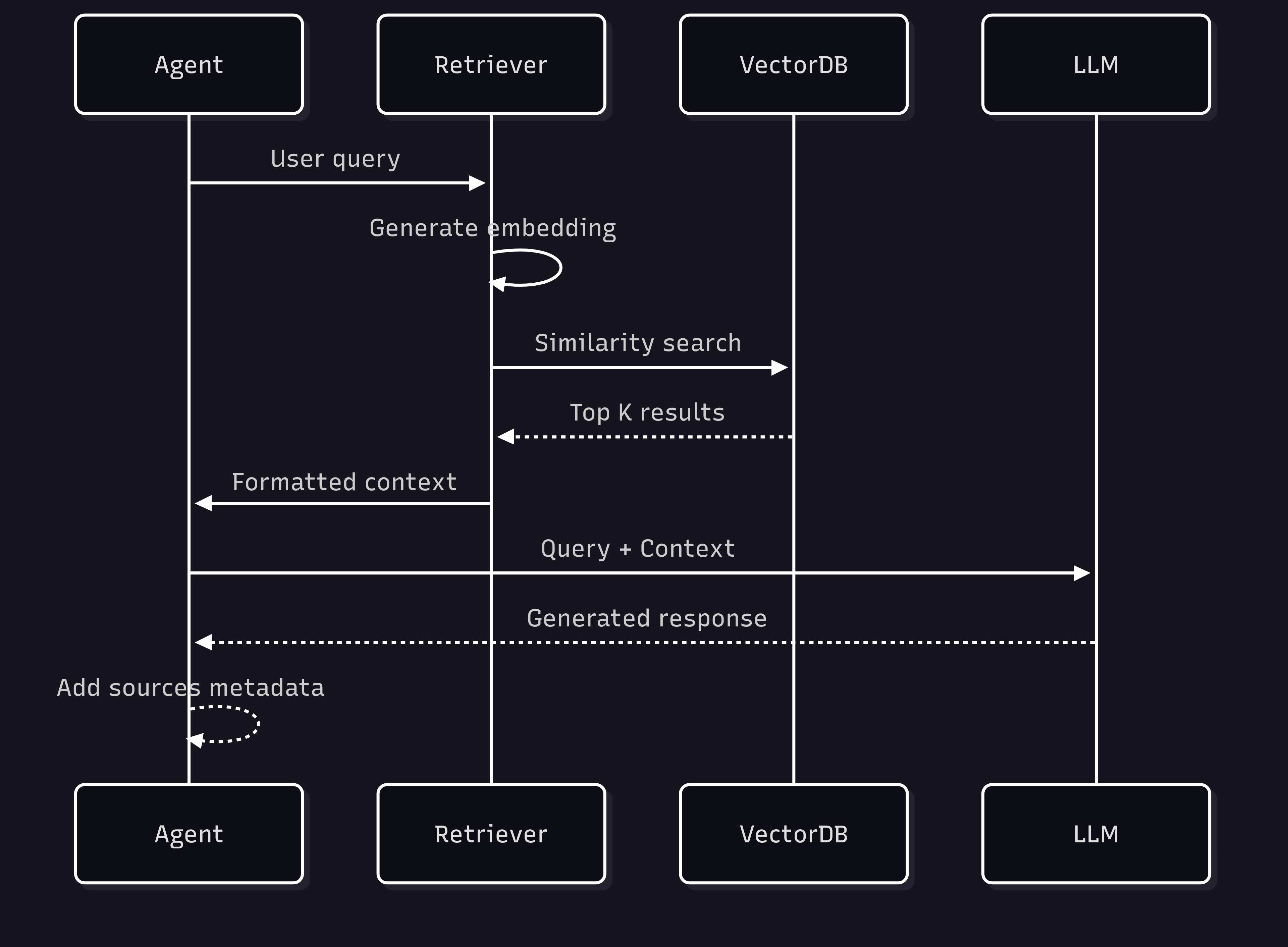
VoltAgent supports multiple vector databases out of the box:
- Chroma - Perfect for local development, runs without Docker
- Pinecone - Fully managed, serverless solution for production
- Qdrant - Open source with both self-hosted and cloud options
Getting started is simple:
# Create a project with Chroma (local development)
npm create voltagent-app@latest -- --example with-chroma
# Or with Pinecone (production)
npm create voltagent-app@latest -- --example with-pinecone
VoltAgent uses a flexible BaseRetriever pattern, so you can switch between vector databases without changing your agent code:
import { Agent } from "@voltagent/core";
import { ChromaRetriever } from "./retriever";
const agent = new Agent({
name: "Support Bot",
instructions: "Help customers with documentation",
retriever: new ChromaRetriever(), // Just swap this for different DBs
});
Learn more in the VoltAgent RAG documentation or check out the examples on GitHub.
Understanding Similarity Metrics
Before diving into how LLMs and vector databases work together, it's crucial to understand how similarity is measured in vector space:
Cosine Similarity
Measures the cosine of the angle between two vectors. Perfect for comparing document similarity regardless of their magnitude:
- Range: -1 to 1 (1 = identical direction)
- Use case: Text similarity, recommendation systems
- Formula:
cos(θ) = (A·B) / (||A|| × ||B||)
Euclidean Distance
Measures the straight-line distance between two points in vector space:
- Range: 0 to ∞ (0 = identical)
- Use case: When magnitude matters (e.g., image similarity)
- Formula:
d = √Σ(Ai - Bi)²
Dot Product
Measures both magnitude and direction:
- Range: -∞ to ∞
- Use case: When both scale and direction matter
- Often fastest to compute
The choice of metric significantly impacts search quality and performance. Most vector databases default to cosine similarity for text embeddings.
How LLMs and Vector Databases Work Together
Large language models are trained on massive datasets, but they still have limitations:
- They don't know your proprietary company data
- They don't have up-to-date information
- They can't capture confidential or rapidly changing information
This is where vector databases come in. Three main use cases stand out:
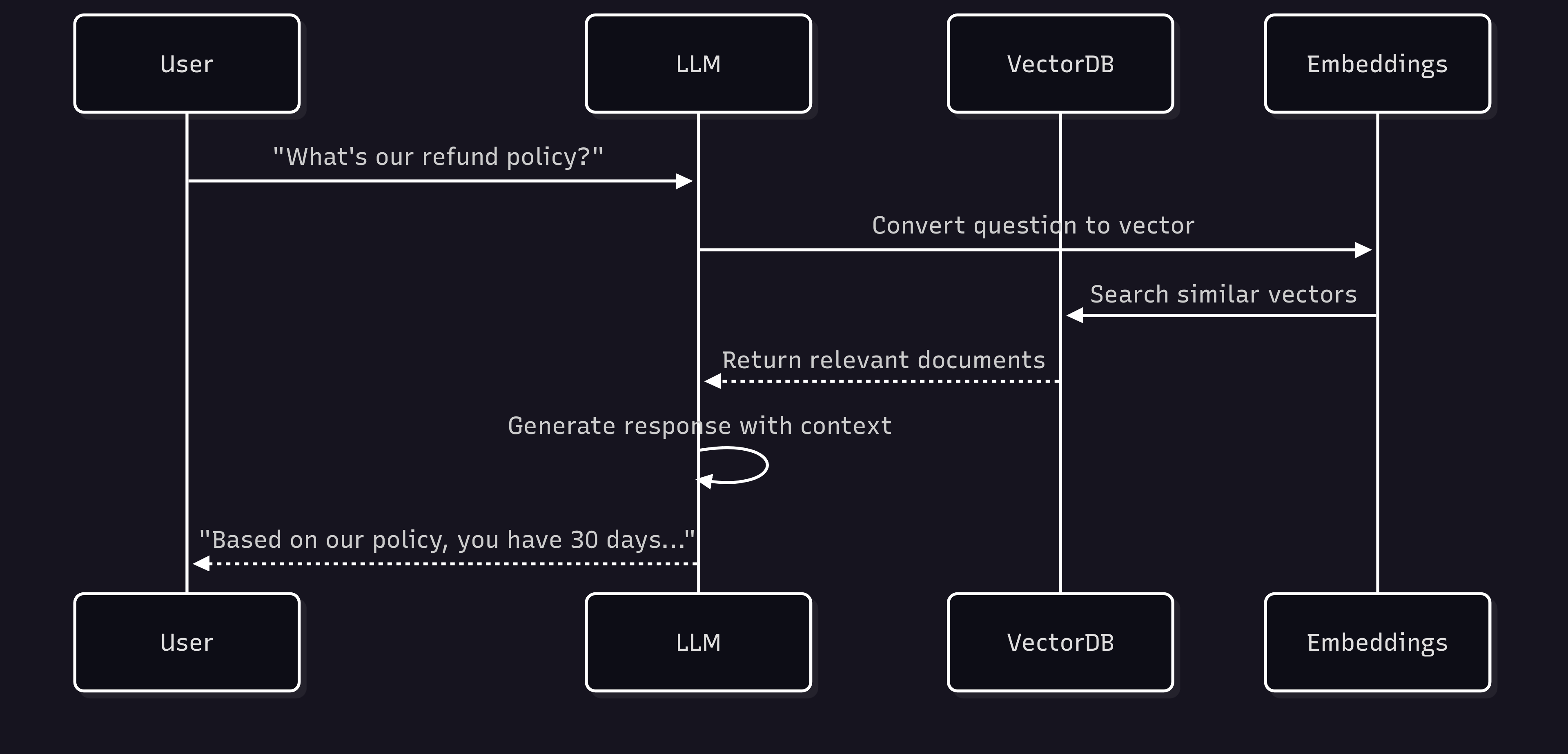
1. Context Retrieval
LLMs can't remember everything. Here, a vector database acts like a Golden Retriever - it fetches the information the model needs. This way, the model gets augmented with data it doesn't know.
2. Memory
Applications like chatbots need to remember previous conversations. Vector databases make memory efficient by storing and retrieving only relevant messages from long dialogues. This approach is similar to ChatGPT's "long-term memory" concept.
3. Caching
When the same or similar questions are asked repeatedly, instead of running the model again, you can return previously generated responses. This approach:
- Reduces computational costs
- Speeds up the application
- Improves user experience
Real-World Use Cases
Question-Answer Systems
The user's question gets converted to an embedding, the most similar content is found in the vector database, and the model generates a response using this context. This method is both cheaper and faster than fine-tuning.
Chatbots
By storing only relevant parts of previous messages, chatbots can provide more natural and consistent responses in conversations.
Finance and Real-Time Data
For information that changes within seconds, like stock trading, fine-tuning is impossible. Vector databases can continuously feed current information to the model.
Performance Comparison: Vector Database Solutions
Here's how popular vector databases stack up in real-world scenarios:
| Database | Query Speed (1M vectors) | Index Build Time | Memory Usage | Best For |
|---|---|---|---|---|
| Pinecone | ~10ms | N/A (managed) | N/A (cloud) | Production, serverless |
| Qdrant | ~15ms | 5-10 min | ~2GB | Self-hosted, flexibility |
| Chroma | ~20ms | 3-5 min | ~1.5GB | Local development |
| Weaviate | ~12ms | 8-12 min | ~2.5GB | Multi-modal search |
| Milvus | ~8ms | 10-15 min | ~3GB | Large-scale deployments |
| Redis | ~5ms | 2-3 min | ~1GB | Hybrid workloads |
Note: Performance varies based on hardware, indexing method, and dataset characteristics.
Key Performance Factors:
- Indexing Algorithm: HNSW generally offers best speed/accuracy trade-off
- Dimension Size: Higher dimensions = slower searches
- Dataset Size: Performance degrades differently across solutions
- Hardware: GPU acceleration can provide 10-100x speedup
Choosing the Right Vector Database
Selecting a vector database depends on your specific requirements. Here's a decision framework:
For Local Development
Choose Chroma or Qdrant if you:
- Need quick prototyping
- Want to avoid cloud costs
- Have < 1M vectors
- Need full control over data
For Production at Scale
Choose Pinecone or Milvus if you:
- Have > 10M vectors
- Need 99.9% uptime SLA
- Want managed infrastructure
- Require horizontal scaling
For Hybrid Workloads
Choose Redis or Weaviate if you:
- Already use Redis/have existing infrastructure
- Need both vector and traditional queries
- Want multi-modal search capabilities
- Require sub-10ms latency
Cost Considerations
| Solution | Cost Model | Approximate Monthly Cost (1M vectors) |
|---|---|---|
| Pinecone | Per vector + queries | $70-150 |
| Qdrant Cloud | Per cluster | $100-300 |
| Self-hosted | Infrastructure only | $50-200 (AWS/GCP) |
| Chroma | Free (local) | $0 |
Common Pitfalls and Best Practices
Pitfalls to Avoid
-
Dimension Mismatch
- Problem: Using different embedding models for indexing and querying
- Solution: Always use the same model version and dimensions
-
Not Normalizing Vectors
- Problem: Inconsistent similarity scores
- Solution: Normalize vectors before indexing when using cosine similarity
-
Ignoring Metadata Filtering
- Problem: Returning irrelevant results despite high similarity
- Solution: Use metadata filters (date, category, access control)
-
Over-indexing
- Problem: Slow inserts and high memory usage
- Solution: Choose appropriate index parameters for your use case
Best Practices
-
Chunk Your Documents Wisely
# Good: Semantic boundaries
chunks = split_by_paragraphs(document, max_tokens=512)
# Bad: Fixed character count
chunks = [doc[i:i+1000] for i in range(0, len(doc), 1000)] -
Implement Hybrid Search
- Combine vector search with keyword search for better results
- Use BM25 for keyword relevance + vector similarity
-
Monitor Search Quality
- Track metrics: precision@k, recall@k, MRR
- A/B test different embedding models
- Log user feedback on search results
-
Handle Edge Cases
- Empty queries: Provide fallback behavior
- Out-of-domain queries: Set similarity thresholds
- Rate limiting: Implement query throttling
Scalability and Production Considerations
Scaling Strategies
-
Vertical Scaling
- Add more RAM for larger indexes
- Use SSDs for faster disk operations
- GPU acceleration for similarity computation
-
Horizontal Scaling
- Shard by metadata (e.g., user_id, tenant_id)
- Replicate for read-heavy workloads
- Use load balancers for query distribution
-
Index Optimization
- IVF (Inverted File): Good for 1M-10M vectors
- HNSW: Best for < 1M vectors with high recall
- LSH: Suitable for streaming data
Production Checklist
- Backup Strategy: Regular snapshots, point-in-time recovery
- Monitoring: Query latency, index size, memory usage
- Security: Encryption at rest/transit, API authentication
- Disaster Recovery: Multi-region deployment, failover plan
- Version Control: Track embedding model versions
- Data Pipeline: Automated ingestion and updates
- Cost Optimization: Index pruning, cold storage for old data
Real-World Architecture Example
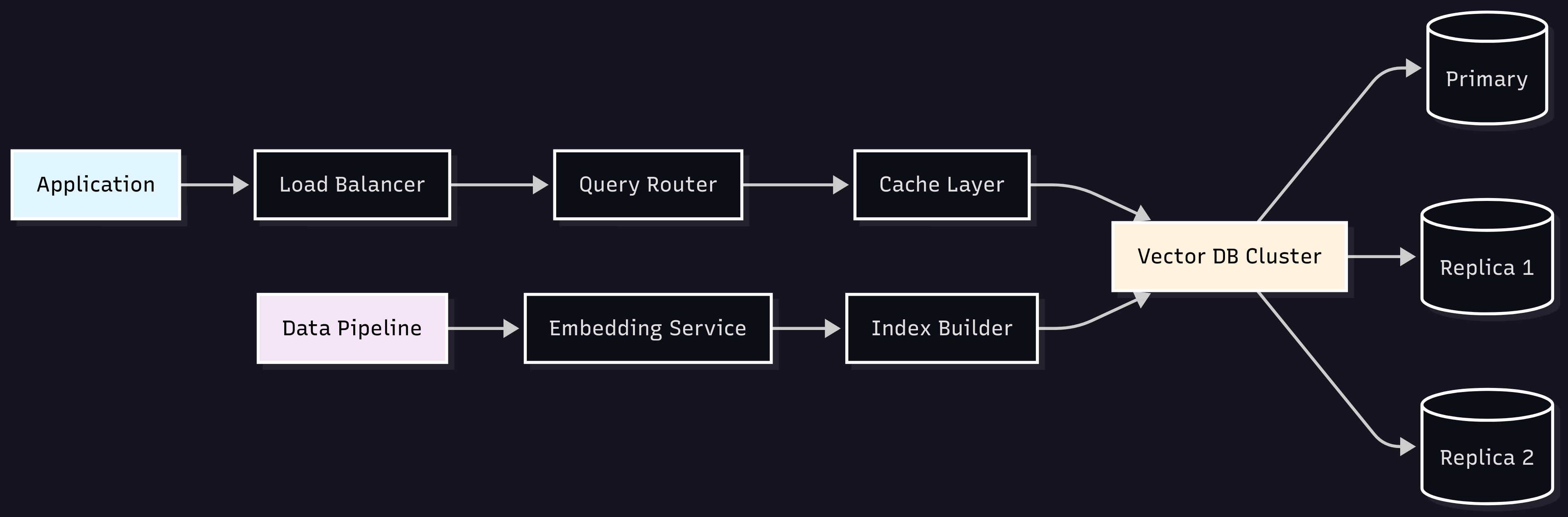
Conclusion
Vector databases make large language models smarter, more current, and more economical. Solutions like Redis make it much easier to bring these integrations to production environments.
Here's my take: we now clearly see that LLMs alone aren't enough. The real value comes when we combine them with the right infrastructure like vector databases. This gives us both the opportunity to develop more powerful applications and the chance to reduce costs.