
"ChatGPT is amazing, but how do I integrate this into my own app?" - How many developers have heard this question...
LLMs changed our lives, no doubt about it. Since ChatGPT came out, everyone sees incredible possibilities. But let me tell you the truth as a developer: Using this power in our own applications is way harder than we thought.
Most of us go through the same cycle. First there's excitement: "I have an amazing AI idea!" Then quick start: We do API integration, simple examples work, everything looks good. But when real users come... that's when everything gets complicated. Code becomes unmanageable, every new feature breaks old code, debugging becomes a nightmare.
Did you go through this cycle? You're not alone.
The Real Problem: From API to Application
When you look at AI development with the traditional approach, it looks like this:
// Manual API call every time
const response = await openai.chat.completions.create({
messages: [{ role: "user", content: userInput }],
});
// Custom code for every feature...
No problem at first. But then user requests start coming: "Can it use this tool?", "Can it remember past conversations?", "Can it behave differently in different situations?" You write code from scratch for every request. You solve the same problems over and over.
This is where an LLM agent framework comes in right here. They hide complexity behind abstraction layers:
// Define agent once, complexity handled by framework
const agent = new Agent({
name: "customer-support",
instructions: "Do customer support",
tools: [orderTool, refundTool],
memory: conversationMemory,
});
See the difference? The framework handles those thousands of lines of boilerplate code, error handling, memory management, tool orchestration and gives you a chance to just focus on business logic.
What's Out There?
At this point, developers have three main options.
Those who choose the DIY approach want full control but their lives become hell. They write everything from scratch, solve the same problems over and over. Might be reasonable for companies with big engineering teams but overkill for most projects.
Those who choose no-code/low-code platforms start fast but then hit walls. Visual editors are nice, don't require technical knowledge at first but when you want a custom feature, you get "you can't do that" as an answer. Vendor lock-in risk is also a pain.
LLM agent framework find a place between the two. They give you ready-made building blocks but don't compromise on flexibility. Production-ready, best practices built-in but you can customize however you want.
When deciding which option to go with, think about these: How's the programming language support? Is switching between LLM providers easy? What's the performance and scalability situation? How's the documentation quality? Is there community support? Are error handling, monitoring, security features good?
Start with a framework if you're building your first AI application. You can always migrate to custom solutions later when you understand your specific needs better.
🎯 Agent Feature Prioritizer
Get personalized recommendations for which agent features to implement first:
Voltagent Example
The following examples show Voltagent's approach, but similar patterns exist in other frameworks like LangChain, AutoGen, and CrewAI. The concepts are transferable.
At this point I want to give a concrete example. While developing Voltagent, we experienced exactly these problems and tried to solve them.
Voltagent's design philosophy is: "Powerful defaults, infinite customization" - meaning provide ready solutions for most use cases, but unlimited flexibility for special needs.
One of our most important decisions was being TypeScript-first. Why? Because type safety really saves lives. In complex agent systems, knowing which function takes what parameters is critical. We also made a modular package system - you only use what you need:
// Only use what you need
import { Agent } from "@voltagent/core";
import { VoiceAgent } from "@voltagent/voice"; // If needed
Provider-agnostic design was also very important. We didn't want vendor lock-in:
// Easy provider switching
const openaiAgent = new Agent({
llm: new VercelAIProvider(),
model: openai("gpt-4o"),
});
const anthropicAgent = new Agent({
llm: new AnthropicProvider(),
model: anthropic("claude-3-5-sonnet"),
});
From Simple Agents to Complex Systems
Creating an agent in its simplest form is really easy:
const agent = new Agent({
name: "My Assistant",
instructions: "Helpful and friendly assistant",
llm: new VercelAIProvider(),
model: openai("gpt-4o"),
});
// Usage is also simple
const response = await agent.generateText("Hello!");
console.log(response.text);
But the beautiful thing is, you can do much more complex stuff with the same API. For example structured data generation:
// Define schema for data extraction
const personSchema = z.object({
name: z.string().describe("Full name"),
age: z.number(),
occupation: z.string(),
skills: z.array(z.string()),
});
// Ask agent for structured data
const result = await agent.generateObject(
"Create a profile for a software developer named Alex.",
personSchema
);
console.log(result.object); // Type-safe JSON object
This feature is especially useful for data extraction and API responses. You're not saying "give it in JSON format" and then trying to parse it anymore.
Tool Integration: Real World Connection
We added MCP (Model Context Protocol) support in the tool integration part. This really became a game-changing feature:
// Define local tool
const weatherTool = createTool({
name: "get_weather",
description: "Get the current weather for a specific location",
parameters: z.object({
location: z.string().describe("City and state"),
}),
execute: async ({ location }) => {
// Real API call would be here
return { temperature: 72, conditions: "sunny" };
},
});
// Connect to external MCP server
const mcpTools = await connectMCPServer("stdio://weather-server");
const agent = new Agent({
name: "Weather Assistant",
instructions: "Can check weather using available tools",
llm: new VercelAIProvider(),
model: openai("gpt-4o"),
tools: [weatherTool, ...mcpTools], // Combine both
});
The agent decides which tool to use when by itself. You just say "How's the weather in London?", it calls its own tool and brings you the result.
Memory: Context Management
We also carefully designed the memory system. It's critical for agents to remember past conversations:
import { LibSQLStorage } from "@voltagent/core";
const memoryStorage = new LibSQLStorage({
url: "file:local.db",
});
const agent = new Agent({
name: "Assistant with Memory",
instructions: "Remember our conversation history",
llm: new VercelAIProvider(),
model: openai("gpt-4o"),
memory: memoryStorage, // Automatic context management
});
// First conversation
await agent.generateText("My name is John and I love pizza");
// Next conversation - will remember the previous one
await agent.generateText("What's my favorite food?");
// "Based on our previous conversation, you love pizza!"
The framework automatically fetches relevant context and saves new interactions.
Multi-Agent Systems
One of my favorite features is the sub-agent system. You can break complex tasks into small pieces and distribute them to expert agents:
const researchAgent = new Agent({
name: "Researcher",
instructions: "Research topics thoroughly using web search",
tools: [webSearchTool],
});
const writerAgent = new Agent({
name: "Writer",
instructions: "Write engaging content based on research",
tools: [contentGenerator],
});
const coordinator = new Agent({
name: "Coordinator",
instructions: "Coordinate research and writing tasks",
llm: new VercelAIProvider(),
model: openai("gpt-4o"),
subAgents: [researchAgent, writerAgent], // Automatic delegate_task tool
});
// Complex workflow in a single call
await coordinator.generateText("Write a blog post about quantum computing");
// Coordinator will give research to researcher, writing to writer
Memory management and tool integration are the foundation of production-ready agents. Without these, you'll hit scaling issues quickly as your application grows.
Debugging and Monitoring: Hooks System
One of my favorite features is also the visual console for debugging. I saw this approach for the first time in the framework world. But there's also a hooks system at the code level:
const hooks = createHooks({
onStart: async ({ agent, context }) => {
const requestId = `req-${Date.now()}`;
context.context.set("requestId", requestId);
console.log(`[${agent.name}] Started: ${requestId}`);
},
onToolStart: async ({ agent, tool, context }) => {
const reqId = context.context.get("requestId");
console.log(`[${reqId}] Tool starting: ${tool.name}`);
},
onToolEnd: async ({ agent, tool, output, context }) => {
const reqId = context.context.get("requestId");
console.log(`[${reqId}] Tool finished: ${tool.name}`, output);
},
onEnd: async ({ agent, output, context }) => {
const reqId = context.context.get("requestId");
console.log(`[${reqId}] Operation complete`);
},
});
const agent = new Agent({
name: "Observable Agent",
// ... other config
hooks, // Full traceability
});
This system is very valuable in production. You can trace every tool call, every agent interaction.
Voice Capabilities
Voice integration is also one of the features we added recently. We have both OpenAI and ElevenLabs support:
import { ElevenLabsVoiceProvider } from "@voltagent/voice";
const voiceProvider = new ElevenLabsVoiceProvider({
apiKey: process.env.ELEVENLABS_API_KEY,
voice: "Rachel",
});
const agent = new Agent({
name: "Voice Assistant",
instructions: "A helpful voice assistant",
llm: new VercelAIProvider(),
model: openai("gpt-4o"),
voice: voiceProvider,
});
// Generate text response
const response = await agent.generateText("Tell me a short story");
// Convert to voice
if (agent.voice && response.text) {
const audioStream = await agent.voice.speak(response.text);
// Save audioStream to file or play it
}
Speech-to-text is there too, you can convert audio inputs to text.
VoltOps Platform Experience
npm run dev
# ══════════════════════════════════════════════════
# VOLTAGENT SERVER STARTED SUCCESSFULLY
# ══════════════════════════════════════════════════
# ✓ HTTP Server: http://localhost:3141
# Test your agents with VoltOps Console: https://console.voltagent.dev
# ══════════════════════════════════════════════════
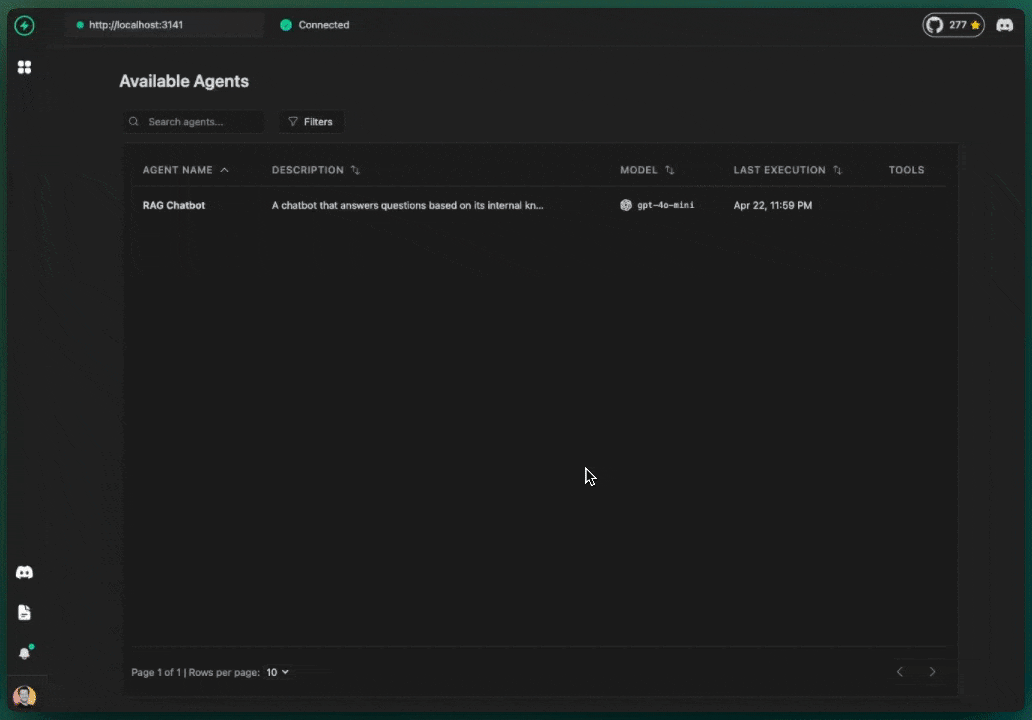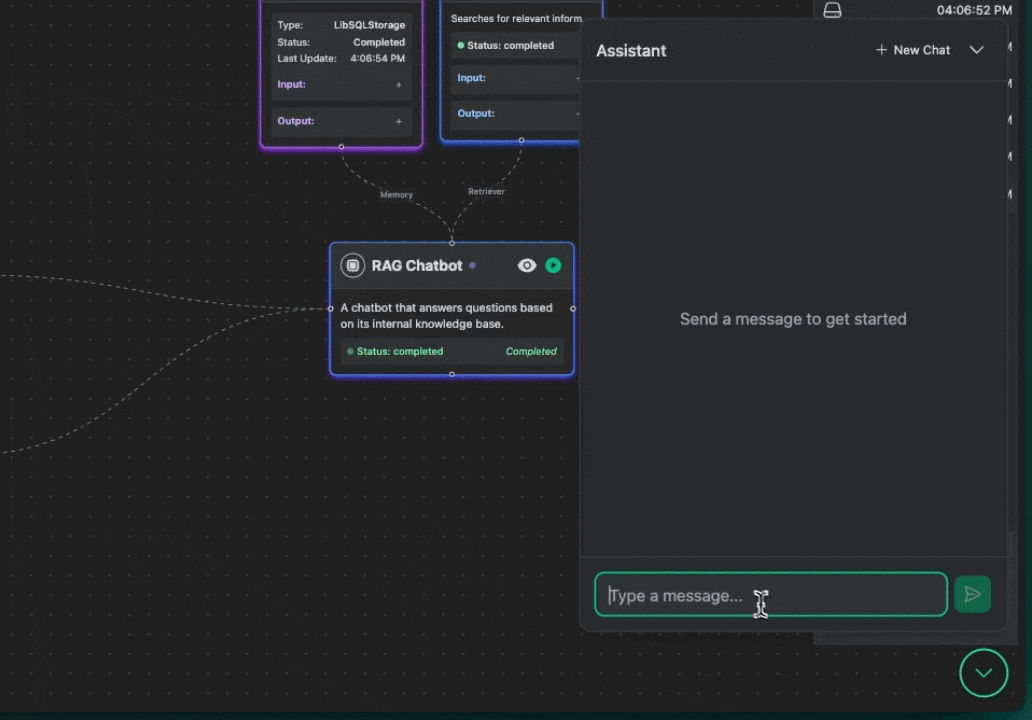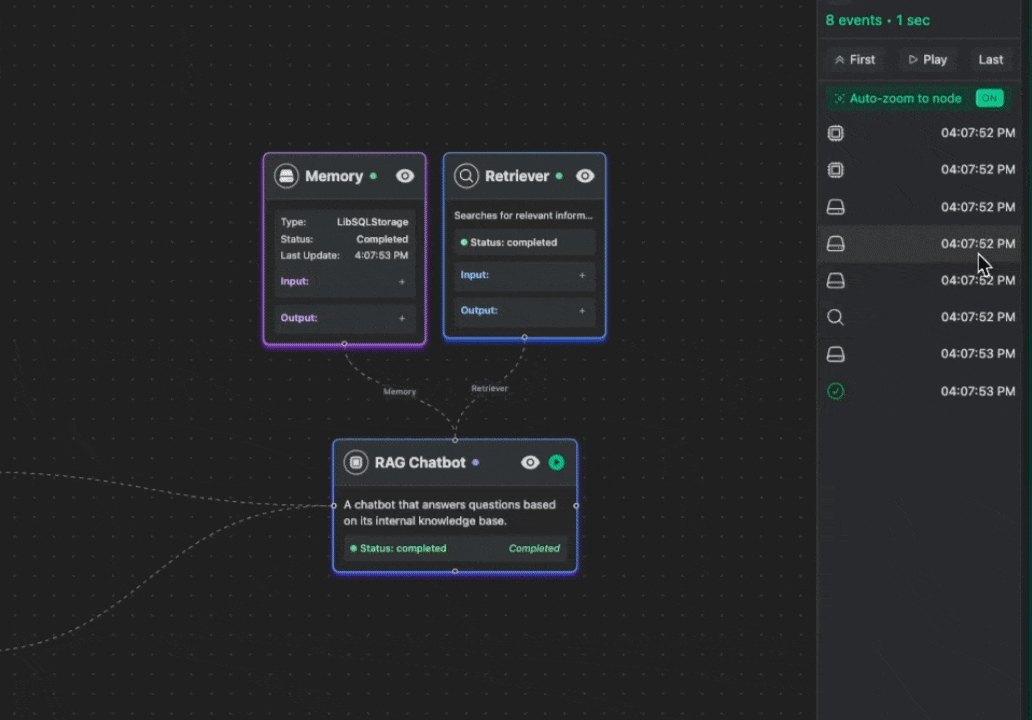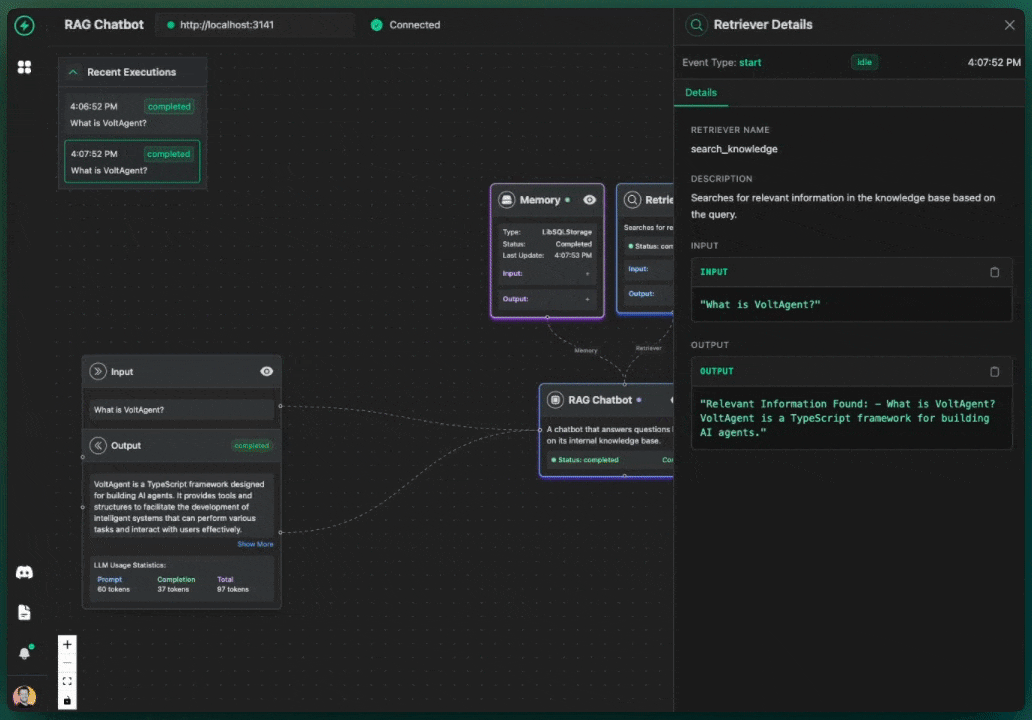
From the console you can do real-time conversation monitoring, tool execution tracing, memory state inspection, performance metrics, error debugging. Debugging has never been this fun.
The best part is, all these features are composable. You can use whatever combination you want - just memory, just tools, just voice, or all of them together. The framework doesn't force you into anything but everything is ready when you need it.
Real World Examples
Examples from the community are really inspiring. Like an e-commerce customer support bot:
const supportAgent = new Agent({
name: "support-bot",
instructions: "E-commerce customer support, can track orders",
tools: [orderLookupTool, refundProcessTool, humanHandoffTool],
memory: new ConversationMemory(),
});
This system achieved 35% less human escalation, 60% faster response time, 24/7 availability.
A developer made a repository analysis tool:
const codeAnalyzer = new Agent({
name: "code-analyzer",
instructions: "Analyze repository, make suggestions",
tools: [githubConnector, codeQualityAnalyzer, documentationChecker],
});
Their feedback was: "I made a production-ready tool in 3 days, normally it would take weeks!"
A company also set up a RAG system for their documentation:
const retrieverAgent = new Agent({
name: "document-finder",
instructions: "Find relevant documents from vector DB",
tools: [vectorSearchTool, rankingTool],
});
const responderAgent = new Agent({
name: "answer-generator",
instructions: "Create detailed answer using context",
subAgents: [retrieverAgent],
});
Performance and Cost Reality
LLM costs can escalate quickly in production. A single poorly optimized agent can burn through hundreds of dollars per day. Always implement cost monitoring from day one.
AI services are expensive, let's not forget that. But you can save serious money with the right optimizations. You can filter unnecessary tokens with smart context compression, you don't make API calls again for the same questions with response caching, you combine operations with batch processing.
💰 Cost Optimization Calculator
Discover strategies to reduce your LLM costs while maintaining quality:
My favorite feature is intelligent model selection:
const adaptiveAgent = new Agent({
name: "smart-agent",
model: adaptiveModel({
simple: "gpt-4o-mini", // Simple tasks
complex: "gpt-4o", // Complex reasoning
coding: "claude-3-5-sonnet", // Code writing
}),
});
Typical results are around 30-50% token savings.
Scaling challenges exist too of course. Memory management becomes difficult when thousands of agents run simultaneously, you need to be careful not to exceed provider API limits, the system should continue when an agent fails. To solve these, you need systems like connection pooling, circuit breaker pattern, automatic retry, graceful degradation.
Community and Ecosystem
The most valuable asset of frameworks is their community. Open source frameworks have these advantages: community contributions, transparency, customization freedom, no vendor lock-in. Commercial solutions offer professional support, enterprise features, SLA guarantees.
In Voltagent for example, MCP integration came from the community, now it's a core feature. Voice improvements, provider extensions, real-world examples - all community contributions.
Future Trends
Multi-modal agents are coming - text + vision + audio capabilities are combining. There's an autonomous learning trend - agents improving themselves. Agent-to-agent communication will become widespread, we'll see cross-organization agent networks. Edge deployment is also growing - lightweight agents running in browsers. No-code builders are developing for non-technical users.
Practical Tips
When choosing a framework, start small, test with a pilot project. Evaluate the community - how are documentation, support, examples? Think about migration path - how hard will it be if you need to change frameworks?
Build a simple chatbot first, then gradually add memory, tools, and multi-agent features. This approach helps you understand each component before building complex systems.
During development give specific instructions - not "do everything", but clear tasks. Apply single responsibility principle in tool design. Think about your memory strategy - how much context, how long? Don't neglect error handling - graceful failures, user experience is important.
When going to production don't forget monitoring setup - metrics, alerting, debugging. Keep API costs under control with rate limiting. Don't neglect security - input validation, output filtering. Do load testing, performance optimization for scalability.
Conclusion
The AI agent space is evolving rapidly. What you build today should be flexible enough to adapt to new models, capabilities, and paradigms that will emerge in the coming months.
LLM Agent Framework aren't just a technology. They're building the foundation of AI-first software development. By the end of 2025, every software company will have AI agents, LLM agent frameworks will become part of the standard development stack, multi-modal interaction will become normal, cost/performance ratio will improve dramatically.
To get started, research existing frameworks - Voltagent, LangChain, AutoGen and others. Try with a small pilot project. Read documentation, check examples, join communities. Test with real users.
This post is just the beginning. AI agent technology is developing so fast that in 6 months there will be new trends, new frameworks, new possibilities. What matters is being part of this transformation.