VoltAgent with Chroma
Chroma is an AI-native open-source vector database designed to make it easy to build applications with embeddings. It handles the complexity of vector storage and search while providing a simple API for semantic search capabilities.
Prerequisites
Before starting, ensure you have:
- Node.js 18+ installed
- OpenAI API key (for embeddings)
Note: Docker or Python are no longer required since Chroma CLI is now bundled with the JS/TS package.
Installation
Create a new VoltAgent project with Chroma integration:
npm create voltagent-app@latest -- --example with-chroma
cd with-chroma
This creates a complete VoltAgent + Chroma setup with sample data and two different agent configurations.
Install the dependencies:
- npm
- pnpm
- yarn
npm install
pnpm install
yarn install
Start Chroma Server
Simply run the following command:
npm run chroma run
This will start the Chroma server at http://localhost:8000.
Note: For production deployments, you might prefer Chroma Cloud, a fully managed hosted service. See the Environment Setup section below for cloud configuration.
Environment Setup
Create a .env file with your configuration:
Option 1: Local Chroma Server
# OpenAI API key for embeddings and LLM
OPENAI_API_KEY=your-openai-api-key-here
# Local Chroma server configuration (optional - defaults shown)
CHROMA_HOST=localhost
CHROMA_PORT=8000
Option 2: Chroma Cloud
# OpenAI API key for embeddings and LLM
OPENAI_API_KEY=your-openai-api-key-here
# Chroma Cloud configuration
CHROMA_API_KEY=your-chroma-cloud-api-key
CHROMA_TENANT=your-tenant-name
CHROMA_DATABASE=your-database-name
The code will automatically detect which configuration to use based on the presence of CHROMA_API_KEY.
Run Your Application
Start your VoltAgent application:
- npm
- pnpm
- yarn
npm run dev
pnpm dev
yarn dev
You'll see:
🚀 VoltAgent with Chroma is running!
📚 Sample knowledge base initialized with 5 documents
📚 Two different agents are ready:
1️⃣ Assistant with Retriever - Automatic semantic search on every interaction
2️⃣ Assistant with Tools - LLM decides when to search autonomously
💡 Chroma server started easily with npm run chroma run (no Docker/Python needed!)
══════════════════════════════════════════════════
VOLTAGENT SERVER STARTED SUCCESSFULLY
══════════════════════════════════════════════════
✓ HTTP Server: http://localhost:3141
↪ Share it: pnpm volt tunnel 3141 (secure HTTPS tunnel for teammates)
Docs: https://voltagent.dev/deployment-docs/local-tunnel/
✓ Swagger UI: http://localhost:3141/ui
Test your agents with VoltOps Console: https://console.voltagent.dev
══════════════════════════════════════════════════
Interact with Your Agents
Your agents are now running! To interact with them:
- Open the Console: Click the
https://console.voltagent.devlink in your terminal output (or copy-paste it into your browser). - Find Your Agents: On the VoltOps LLM Observability Platform page, you should see both agents listed:
- "Assistant with Retriever"
- "Assistant with Tools"
- Open Agent Details: Click on either agent's name.
- Start Chatting: On the agent detail page, click the chat icon in the bottom right corner to open the chat window.
- Test RAG Capabilities: Try questions like:
- "What is VoltAgent?"
- "Tell me about vector databases"
- "How does TypeScript help with development?"
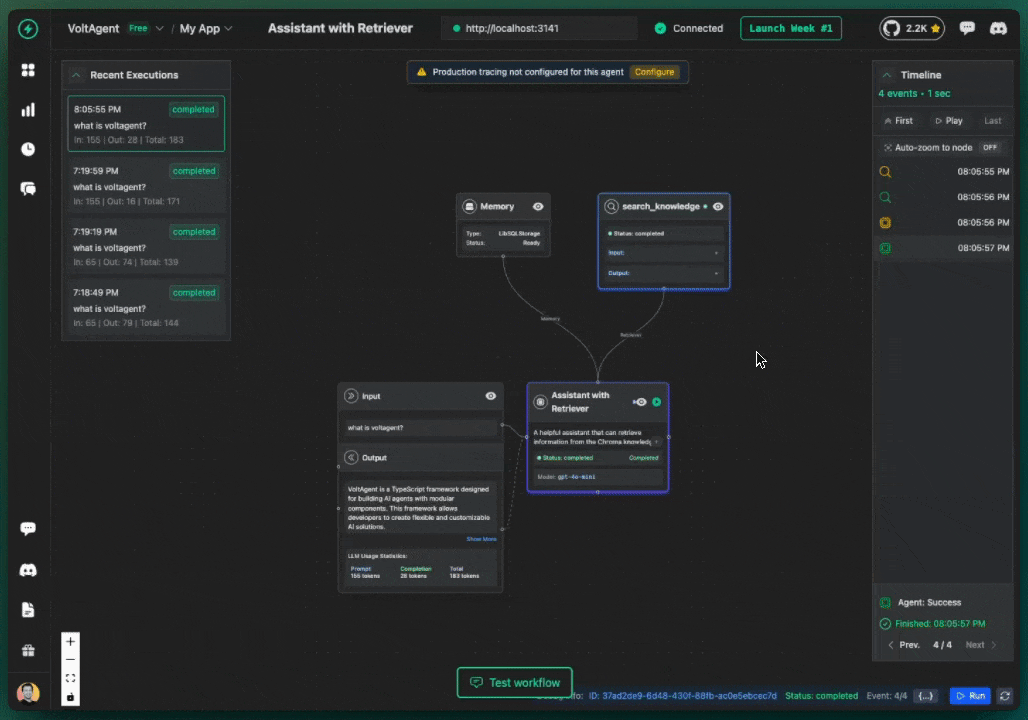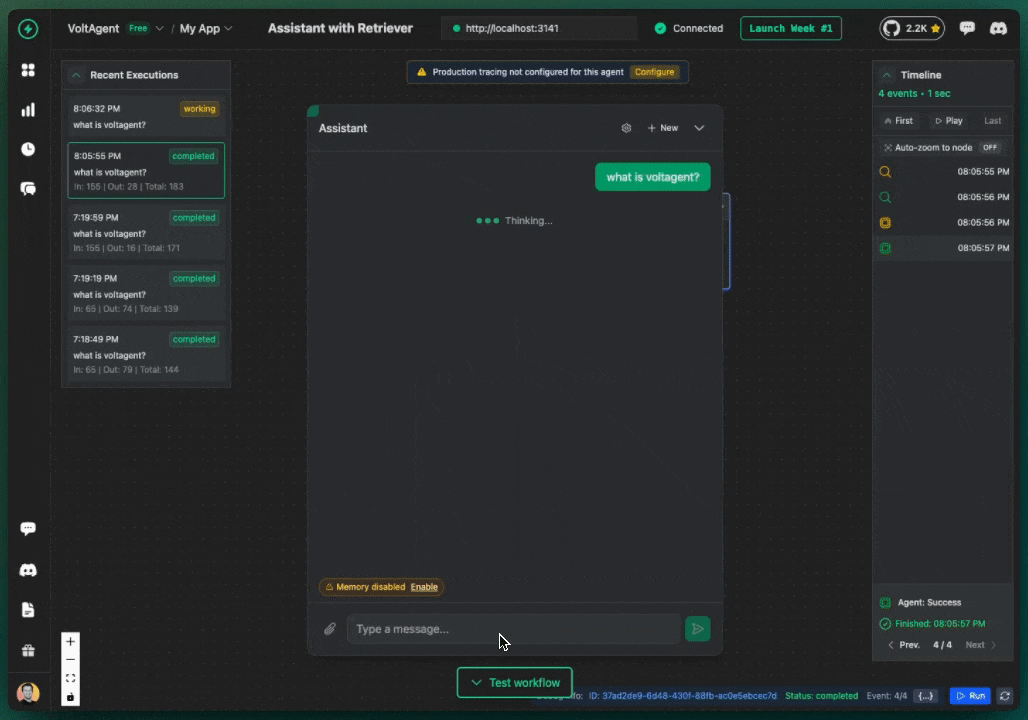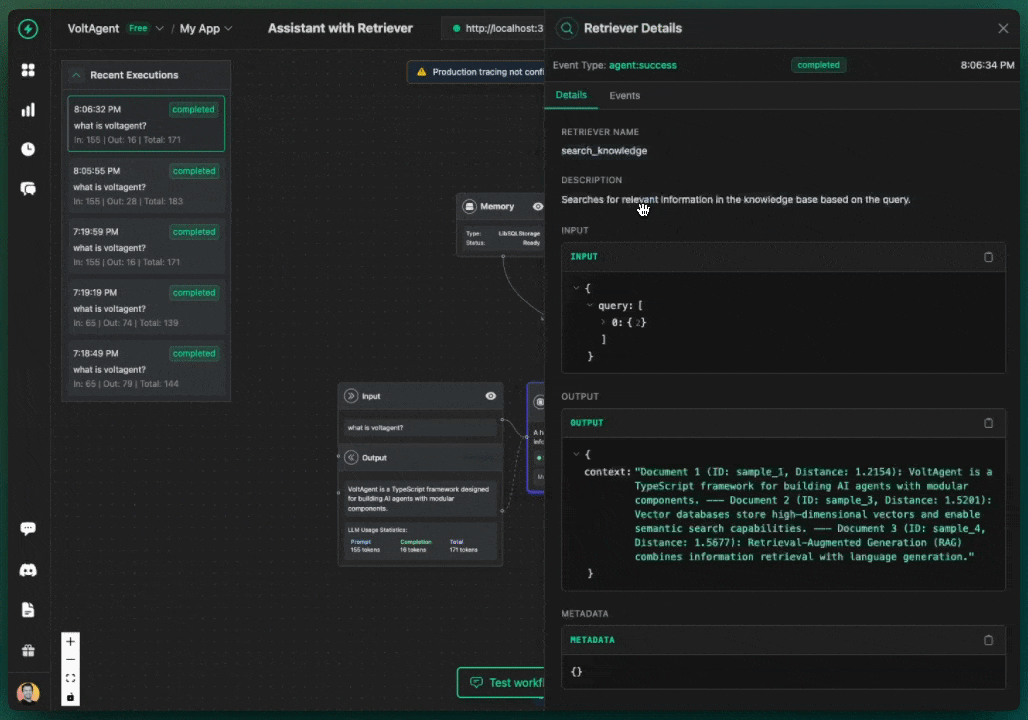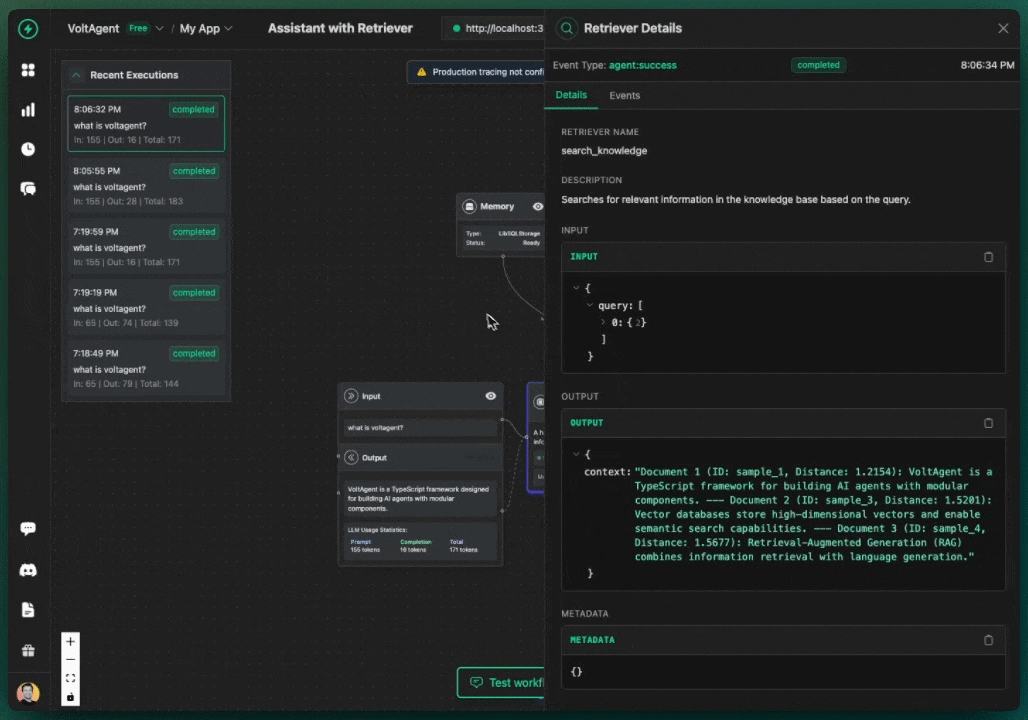
You should receive responses from your AI agents that include relevant information from your Chroma knowledge base, along with source references showing which documents were used to generate the response.
How It Works
The following sections explain how this example is built and how you can customize it.
Create the Chroma Retriever
Create src/retriever/index.ts:
import { BaseRetriever, type BaseMessage, type RetrieveOptions } from "@voltagent/core";
import { ChromaClient, CloudClient, type QueryRowResult, type Metadata } from "chromadb";
import { OpenAIEmbeddingFunction } from "@chroma-core/openai";
// Initialize Chroma client - supports both local and cloud
const chromaClient = process.env.CHROMA_API_KEY
? new CloudClient() // Uses CHROMA_API_KEY, CHROMA_TENANT, CHROMA_DATABASE env vars
: new ChromaClient({
host: process.env.CHROMA_HOST || "localhost",
port: parseInt(process.env.CHROMA_PORT || "8000"),
});
// Configure OpenAI embeddings
const embeddingFunction = new OpenAIEmbeddingFunction({
apiKey: process.env.OPENAI_API_KEY,
modelName: "text-embedding-3-small", // Efficient and cost-effective
});
const collectionName = "voltagent-knowledge-base";
Key Components Explained:
- ChromaClient/CloudClient: Connects to your local Chroma server or Chroma Cloud
- Automatic Detection: Uses CloudClient if CHROMA_API_KEY is set, otherwise falls back to local ChromaClient
- OpenAIEmbeddingFunction: Uses OpenAI's embedding models to convert text into vectors
- Collection: A named container for your documents and their embeddings
Initialize Sample Data
Add sample documents to get started:
async function initializeCollection() {
try {
const collection = await chromaClient.getOrCreateCollection({
name: collectionName,
embeddingFunction: embeddingFunction,
});
// Sample documents about your domain
const sampleDocuments = [
"VoltAgent is a TypeScript framework for building AI agents with modular components.",
"Chroma is an AI-native open-source vector database that handles embeddings automatically.",
"Vector databases store high-dimensional vectors and enable semantic search capabilities.",
"Retrieval-Augmented Generation (RAG) combines information retrieval with language generation.",
"TypeScript provides static typing for JavaScript, making code more reliable and maintainable.",
];
const sampleIds = sampleDocuments.map((_, index) => `sample_${index + 1}`);
// Use upsert to avoid duplicates
await collection.upsert({
documents: sampleDocuments,
ids: sampleIds,
metadatas: sampleDocuments.map((_, index) => ({
type: "sample",
index: index + 1,
topic: index < 2 ? "frameworks" : index < 4 ? "databases" : "programming",
})),
});
console.log("📚 Sample knowledge base initialized");
} catch (error) {
console.error("Error initializing collection:", error);
}
}
// Initialize when module loads
initializeCollection();
What This Does:
- Creates a collection with OpenAI embedding function
- Adds sample documents with metadata
- Uses
upsertto avoid duplicate documents - Automatically generates embeddings for each document
Implement the Retriever Class
Create the main retriever class:
async function retrieveDocuments(query: string, nResults = 3) {
try {
const collection = await chromaClient.getOrCreateCollection({
name: collectionName,
embeddingFunction: embeddingFunction,
});
const results = await collection.query({
queryTexts: [query],
nResults,
});
// Use the new .rows() method for cleaner data access
const rows = results.rows();
if (!rows || rows.length === 0 || !rows[0]) {
return [];
}
// Format results - rows[0] contains the actual row data
return rows[0].map((row: QueryRowResult<Metadata>, index: number) => ({
content: row.document || "",
metadata: row.metadata || {},
distance: results.distances?.[0]?.[index] || 0, // Distance still comes from the original results
id: row.id,
}));
} catch (error) {
console.error("Error retrieving documents:", error);
return [];
}
}
export class ChromaRetriever extends BaseRetriever {
async retrieve(input: string | BaseMessage[], options: RetrieveOptions): Promise<string> {
// Convert input to searchable string
let searchText = "";
if (typeof input === "string") {
searchText = input;
} else if (Array.isArray(input) && input.length > 0) {
const lastMessage = input[input.length - 1];
// Handle different content formats
if (Array.isArray(lastMessage.content)) {
const textParts = lastMessage.content
.filter((part: any) => part.type === "text")
.map((part: any) => part.text);
searchText = textParts.join(" ");
} else {
searchText = lastMessage.content as string;
}
}
// Perform semantic search
const results = await retrieveDocuments(searchText, 3);
// Add references to context for tracking
if (options.context && results.length > 0) {
const references = results.map((doc, index) => ({
id: doc.id,
title: doc.metadata.title || `Document ${index + 1}`,
source: "Chroma Knowledge Base",
distance: doc.distance,
}));
options.context.set("references", references);
}
// Format results for the LLM
if (results.length === 0) {
return "No relevant documents found in the knowledge base.";
}
return results
.map(
(doc, index) =>
`Document ${index + 1} (ID: ${doc.id}, Distance: ${doc.distance.toFixed(4)}):\n${doc.content}`
)
.join("\n\n---\n\n");
}
}
export const retriever = new ChromaRetriever();
Key Features:
- Input Handling: Supports both string and message array inputs
- Semantic Search: Uses Chroma's vector similarity search
- User Context: Tracks references for transparency
- Error Handling: Graceful fallbacks for search failures
Create Your Agents
Now create agents using different retrieval patterns in src/index.ts:
import { Agent, VoltAgent } from "@voltagent/core";
import { honoServer } from "@voltagent/server-hono";
import { retriever } from "./retriever/index.js";
// Agent 1: Automatic retrieval on every interaction
const agentWithRetriever = new Agent({
name: "Assistant with Retriever",
instructions:
"A helpful assistant that automatically searches the knowledge base for relevant information",
model: "openai/gpt-4o-mini",
retriever: retriever,
});
// Agent 2: LLM decides when to search
const agentWithTools = new Agent({
name: "Assistant with Tools",
instructions: "A helpful assistant that can search the knowledge base when needed",
model: "openai/gpt-4o-mini",
tools: [retriever.tool],
});
new VoltAgent({
agents: {
agentWithRetriever,
agentWithTools,
},
server: honoServer(),
});
Usage Patterns
Automatic Retrieval
The first agent automatically searches before every response:
User: "What is VoltAgent?"
Agent: Based on the knowledge base, VoltAgent is a TypeScript framework for building AI agents with modular components...
Sources:
- Document 1 (ID: sample_1, Distance: 0.1234): Chroma Knowledge Base
- Document 2 (ID: sample_2, Distance: 0.2456): Chroma Knowledge Base
Tool-Based Retrieval
The second agent only searches when it determines it's necessary:
User: "Tell me about TypeScript"
Agent: Let me search for relevant information about TypeScript.
[Searches knowledge base]
According to the search results, TypeScript provides static typing for JavaScript, making code more reliable and maintainable...
Sources:
- Document 5 (ID: sample_5, Distance: 0.0987): Chroma Knowledge Base
Accessing Sources in Your Code
You can access the sources that were used in the retrieval from the response:
// After generating a response
const response = await agent.generateText("What is VoltAgent?");
console.log("Answer:", response.text);
// Check what sources were used
const references = response.context?.get("references");
if (references) {
console.log("Used sources:", references);
references.forEach((ref) => {
console.log(`- ${ref.title} (ID: ${ref.id}, Distance: ${ref.distance})`);
});
}
// Output: [{ id: "sample_1", title: "Document 1", source: "Chroma Knowledge Base", distance: 0.1234 }]
Or when using streamText:
const result = await agent.streamText("Tell me about vector databases");
for await (const textPart of result.textStream) {
process.stdout.write(textPart);
}
// Access sources after streaming completes
const references = result.context?.get("references");
if (references) {
console.log("\nSources used:", references);
}
Customization Options
Different Embedding Models
You can use different OpenAI embedding models:
// More powerful but more expensive
const embeddingFunction = new OpenAIEmbeddingFunction({
apiKey: process.env.OPENAI_API_KEY,
modelName: "text-embedding-3-large",
});
// Balanced option
const embeddingFunction = new OpenAIEmbeddingFunction({
apiKey: process.env.OPENAI_API_KEY,
modelName: "text-embedding-3-small",
});
Adding Your Own Documents
To add documents programmatically:
async function addDocument(content: string, metadata: Record<string, any> = {}) {
const collection = await chromaClient.getOrCreateCollection({
name: collectionName,
embeddingFunction: embeddingFunction,
});
const id = `doc_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`;
await collection.add({
documents: [content],
ids: [id],
metadatas: [{ ...metadata, timestamp: new Date().toISOString() }],
});
return id;
}
Filtering Search Results
Chroma supports metadata filtering:
const results = await collection.query({
queryTexts: [query],
nResults: 5,
where: { type: "documentation" }, // Only search docs of this type
});
Best Practices
Embedding Strategy:
- Use
text-embedding-3-smallfor cost efficiency - Use
text-embedding-3-largefor maximum quality - Keep embedding model consistent across documents
Document Management:
- Include relevant metadata for filtering
- Use meaningful document IDs
- Consider document chunking for large texts
Performance:
- Limit search results (3-5 documents typically sufficient)
- Use metadata filtering to narrow searches
- Consider caching for frequently accessed documents
Development:
- Start with sample data to test your setup
- Monitor embedding costs in production
- Implement proper error handling for network issues
Troubleshooting
Chroma Connection Issues:
# Check if Chroma is running
curl http://localhost:8000/api/v1/heartbeat
# Restart Chroma if needed
# If using npm run chroma run, simply stop (Ctrl+C) and restart:
npm run chroma run
# If using Docker:
docker restart <chroma-container-id>
Embedding Errors:
- Verify your OpenAI API key is valid
- Check API quota and billing
- Ensure network connectivity to OpenAI
No Search Results:
- Verify documents were added successfully
- Check embedding function configuration
- Try broader search queries
This integration provides a solid foundation for adding semantic search capabilities to your VoltAgent applications. The combination of VoltAgent's flexible architecture and Chroma's powerful vector search creates a robust RAG system that can handle real-world knowledge retrieval needs.